 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKalman Filter Based Multiple Person Head Tracking
Paper and Code
Jun 11, 2020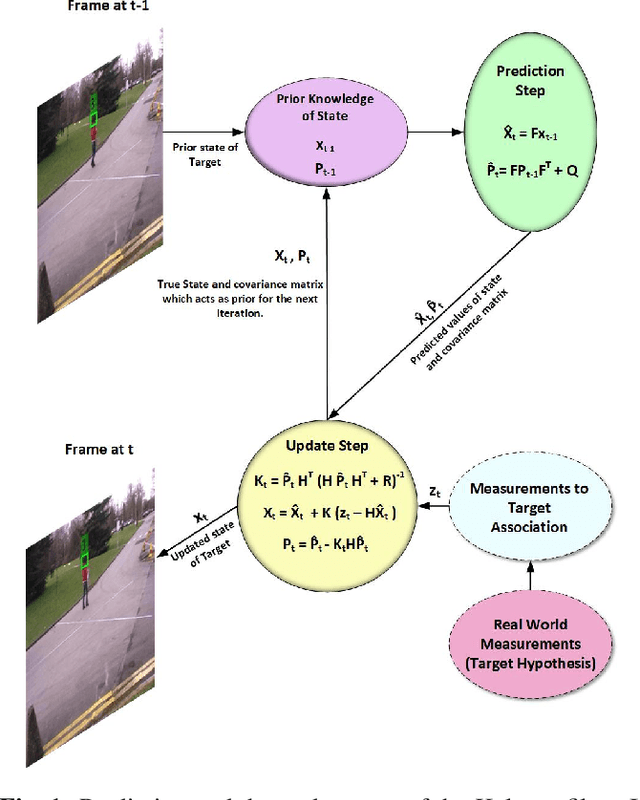

For multi-target tracking, target representation plays a crucial rule in performance. State-of-the-art approaches rely on the deep learning-based visual representation that gives an optimal performance at the cost of high computational complexity. In this paper, we come up with a simple yet effective target representation for human tracking. Our inspiration comes from the fact that the human body goes through severe deformation and inter/intra occlusion over the passage of time. So, instead of tracking the whole body part, a relative rigid organ tracking is selected for tracking the human over an extended period of time. Hence, we followed the tracking-by-detection paradigm and generated the target hypothesis of only the spatial locations of heads in every frame. After the localization of head location, a Kalman filter with a constant velocity motion model is instantiated for each target that follows the temporal evolution of the targets in the scene. For associating the targets in the consecutive frames, combinatorial optimization is used that associates the corresponding targets in a greedy fashion. Qualitative results are evaluated on four challenging video surveillance dataset and promising results has been achieved.