Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCont: Self-Supervised Visual Attribute Disentanglement using Context Vectors
Paper and Code
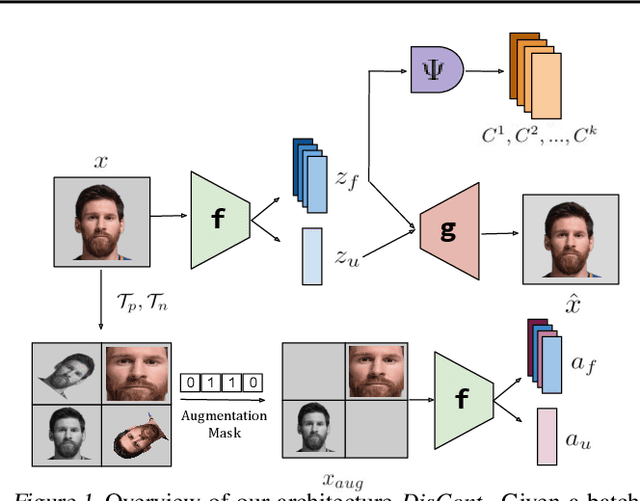
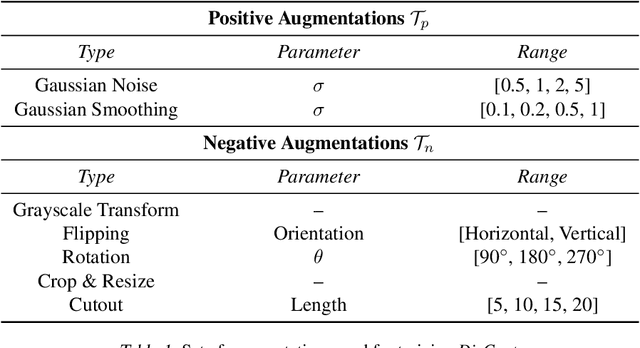
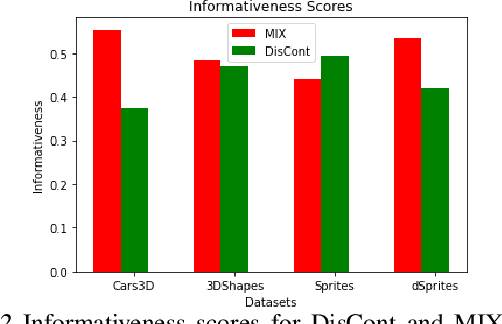

Disentangling the underlying feature attributes within an image with no prior supervision is a challenging task. Models that can disentangle attributes well provide greater interpretability and control. In this paper, we propose a self-supervised framework DisCont to disentangle multiple attributes by exploiting the structural inductive biases within images. Motivated by the recent surge in contrastive learning paradigms, our model bridges the gap between self-supervised contrastive learning algorithms and unsupervised disentanglement. We evaluate the efficacy of our approach, both qualitatively and quantitatively, on four benchmark datasets.
* Published at the 37th International Conference on Machine Learning
(ICML 2020) Workshop on ML Interpretability for Scientific Discovery
View paper on