 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining with Multi-Layer Embeddings for Model Reduction
Paper and Code
Jun 10, 2020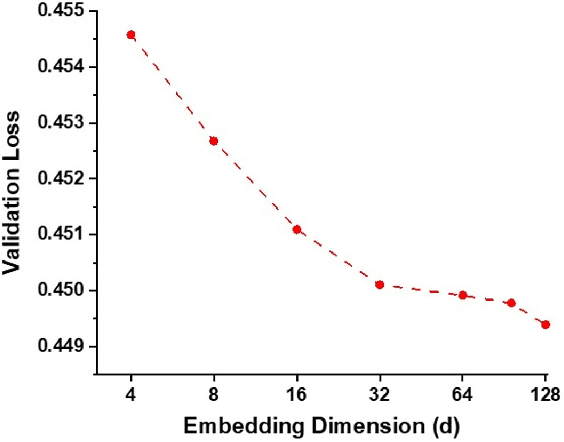

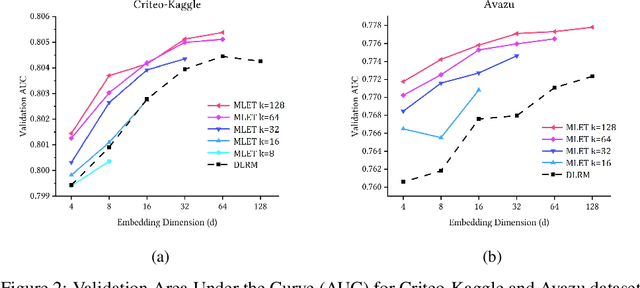
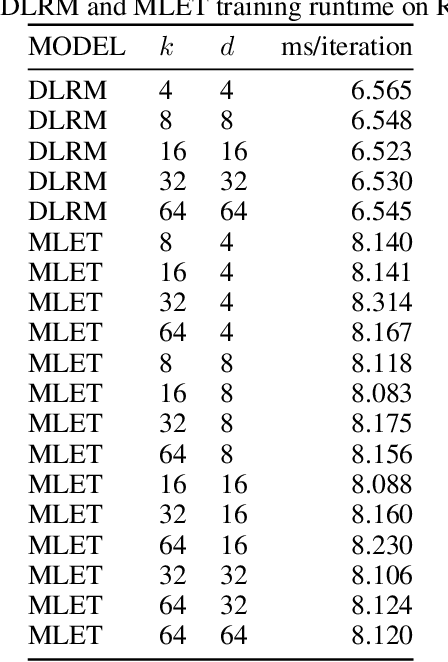
Modern recommendation systems rely on real-valued embeddings of categorical features. Increasing the dimension of embedding vectors improves model accuracy but comes at a high cost to model size. We introduce a multi-layer embedding training (MLET) architecture that trains embeddings via a sequence of linear layers to derive superior embedding accuracy vs. model size trade-off. Our approach is fundamentally based on the ability of factorized linear layers to produce superior embeddings to that of a single linear layer. We focus on the analysis and implementation of a two-layer scheme. Harnessing the recent results in dynamics of backpropagation in linear neural networks, we explain the ability to get superior multi-layer embeddings via their tendency to have lower effective rank. We show that substantial advantages are obtained in the regime where the width of the hidden layer is much larger than that of the final embedding (d). Crucially, at conclusion of training, we convert the two-layer solution into a single-layer one: as a result, the inference-time model size scales as d. We prototype the MLET scheme within Facebook's PyTorch-based open-source Deep Learning Recommendation Model. We show that it allows reducing d by 4-8X, with a corresponding improvement in memory footprint, at given model accuracy. The experiments are run on two publicly available click-through-rate prediction benchmarks (Criteo-Kaggle and Avazu). The runtime cost of MLET is 25%, on average.