 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Cross-Lingual Transfer Learning for End-to-End Speech Recognition with Speech Translation
Paper and Code
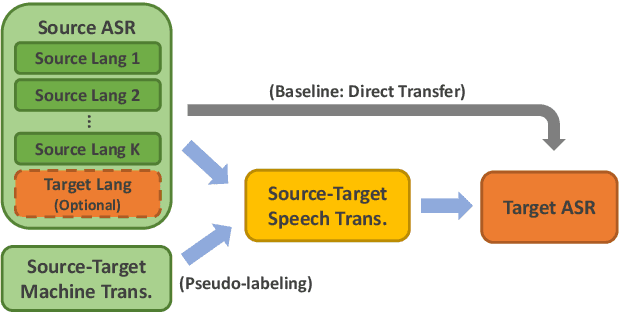
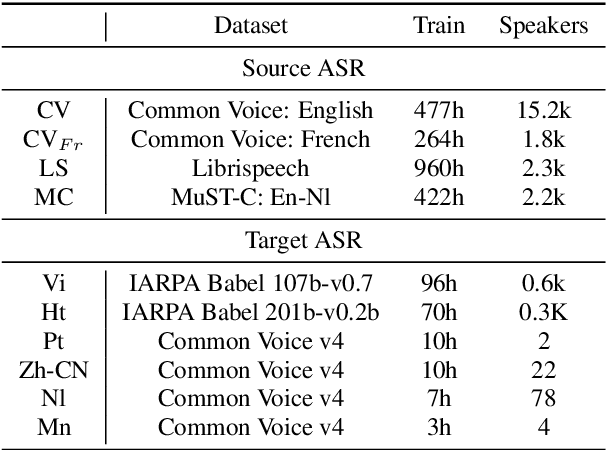
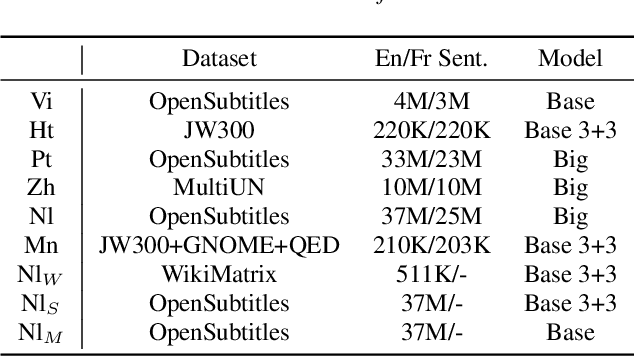
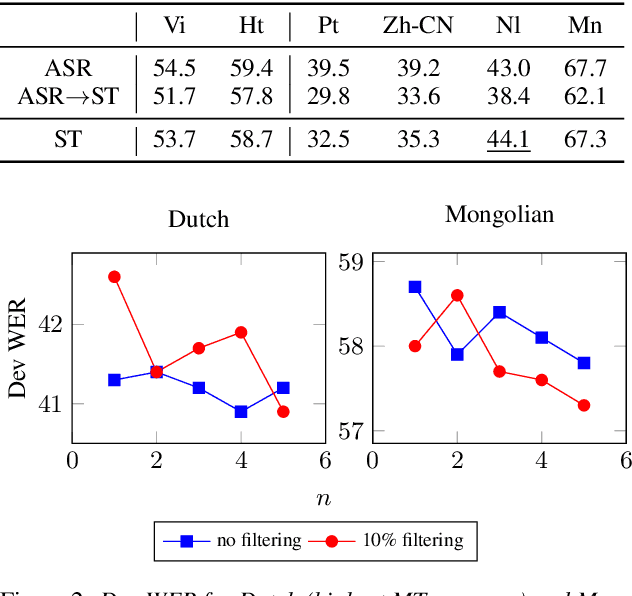
Transfer learning from high-resource languages is known to be an efficient way to improve end-to-end automatic speech recognition (ASR) for low-resource languages. Pre-trained or jointly trained encoder-decoder models, however, do not share the language modeling (decoder) for the same language, which is likely to be inefficient for distant target languages. We introduce speech-to-text translation (ST) as an auxiliary task to incorporate additional knowledge of the target language and enable transferring from that target language. Specifically, we first translate high-resource ASR transcripts into a target low-resource language, with which a ST model is trained. Both ST and target ASR share the same attention-based encoder-decoder architecture and vocabulary. The former task then provides a fully pre-trained model for the latter, bringing up to 24.6% word error rate (WER) reduction to the baseline (direct transfer from high-resource ASR). We show that training ST with human translations is not necessary. ST trained with machine translation (MT) pseudo-labels brings consistent gains. It can even outperform those using human labels when transferred to target ASR by leveraging only 500K MT examples. Even with pseudo-labels from low-resource MT (200K examples), ST-enhanced transfer brings up to 8.9% WER reduction to direct transfer.