 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Under Moral Uncertainty
Paper and Code
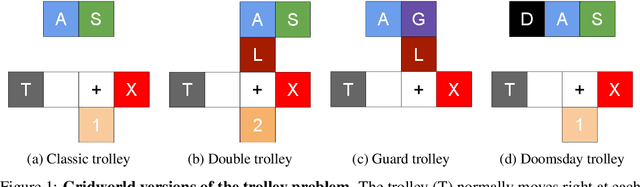
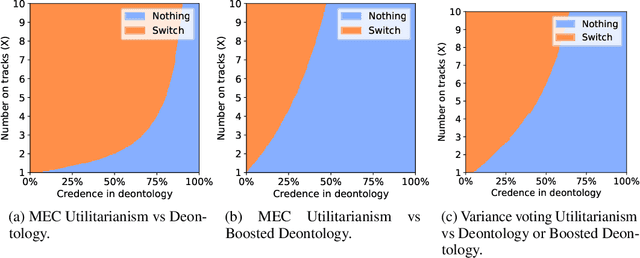
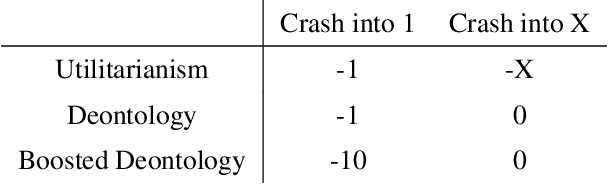
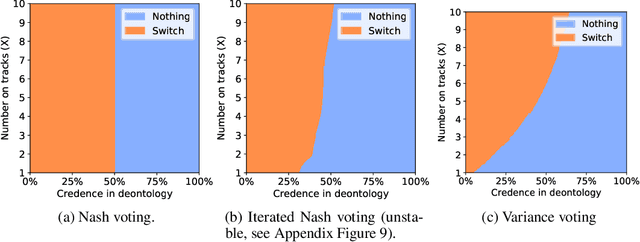
An ambitious goal for artificial intelligence is to create agents that behave ethically: The capacity to abide by human moral norms would greatly expand the context in which autonomous agents could be practically and safely deployed. While ethical agents could be trained through reinforcement, by rewarding correct behavior under a specific moral theory (e.g. utilitarianism), there remains widespread disagreement (both societally and among moral philosophers) about the nature of morality and what ethical theory (if any) is objectively correct. Acknowledging such disagreement, recent work in moral philosophy proposes that ethical behavior requires acting under moral uncertainty, i.e. to take into account when acting that one's credence is split across several plausible ethical theories. Inspired by such work, this paper proposes a formalism that translates such insights to the field of reinforcement learning. Demonstrating the formalism's potential, we then train agents in simple environments to act under moral uncertainty, highlighting how such uncertainty can help curb extreme behavior from commitment to single theories. The overall aim is to draw productive connections from the fields of moral philosophy and machine ethics to that of machine learning, to inspire further research by highlighting a spectrum of machine learning research questions relevant to training ethically capable reinforcement learning agents.