 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable trade-offs between private & robust machine learning
Paper and Code
Jun 08, 2020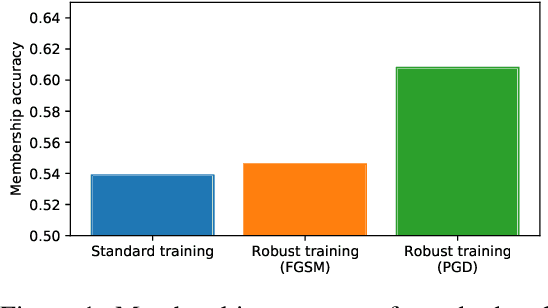

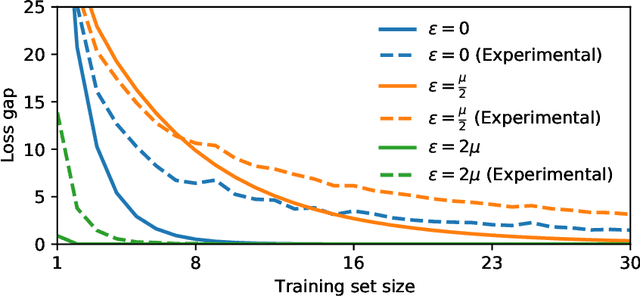
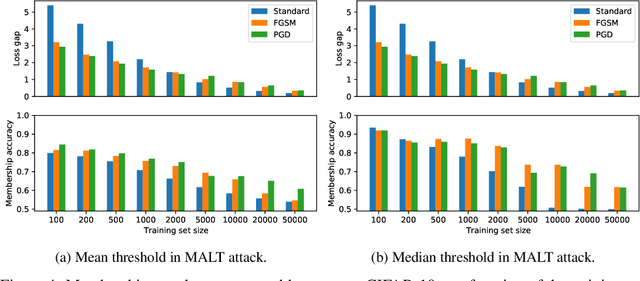
Historically, machine learning methods have not been designed with security in mind. In turn, this has given rise to adversarial examples, carefully perturbed input samples aimed to mislead detection at test time, which have been applied to attack spam and malware classification, and more recently to attack image classification. Consequently, an abundance of research has been devoted to designing machine learning methods that are robust to adversarial examples. Unfortunately, there are desiderata besides robustness that a secure and safe machine learning model must satisfy, such as fairness and privacy. Recent work by Song et al. (2019) has shown, empirically, that there exists a trade-off between robust and private machine learning models. Models designed to be robust to adversarial examples often overfit on training data to a larger extent than standard (non-robust) models. If a dataset contains private information, then any statistical test that separates training and test data by observing a model's outputs can represent a privacy breach, and if a model overfits on training data, these statistical tests become easier. In this work, we identify settings where standard models will provably overfit to a larger extent in comparison to robust models, and as empirically observed in previous works, settings where the opposite behavior occurs. Thus, it is not necessarily the case that privacy must be sacrificed to achieve robustness. The degree of overfitting naturally depends on the amount of data available for training. We go on to formally characterize how the training set size factors into the privacy risks exposed by training a robust model. Finally, we empirically show our findings hold on image classification benchmark datasets, such as CIFAR-10.