 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS-Embed-francesita at SemEval-2020 Task 9: The effectiveness of code-switched word embeddings for sentiment analysis
Paper and Code


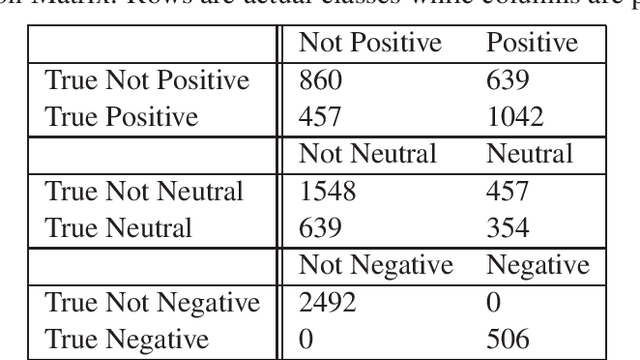
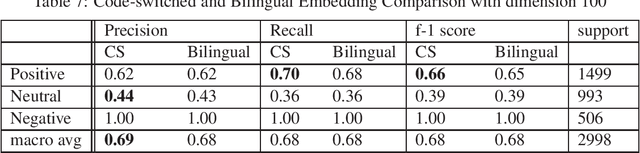
The growing popularity and applications of sentiment analysis of social media posts has naturally led to sentiment analysis of posts written in multiple languages, a practice known as code-switching. While recent research into code-switched posts has focused on the use of multilingual word embeddings, these embeddings were not trained on code-switched data. In this work, we present word-embeddings trained on code-switched tweets, specifically those that make use of Spanish and English, known as Spanglish. We explore the embedding space to discover how they capture the meanings of words in both languages. We test the effectiveness of these embeddings by participating in SemEval 2020 Task 9: ~\emph{Sentiment Analysis on Code-Mixed Social Media Text}. We utilising them to train a sentiment classifier that achieves an F-1 score of 0.722. This is higher than the baseline for the competition of 0.656, and our team ranks 14 out of 23 participating teams beating the baseline.