 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassive Batch Injection Training Technique: Boosting Network Performance by Injecting Mini-Batches from a different Data Distribution
Paper and Code
Jun 08, 2020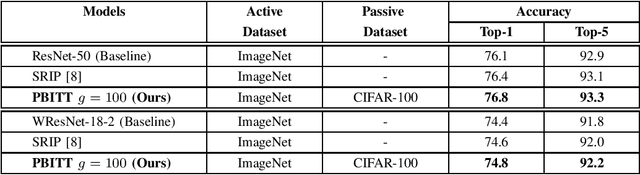
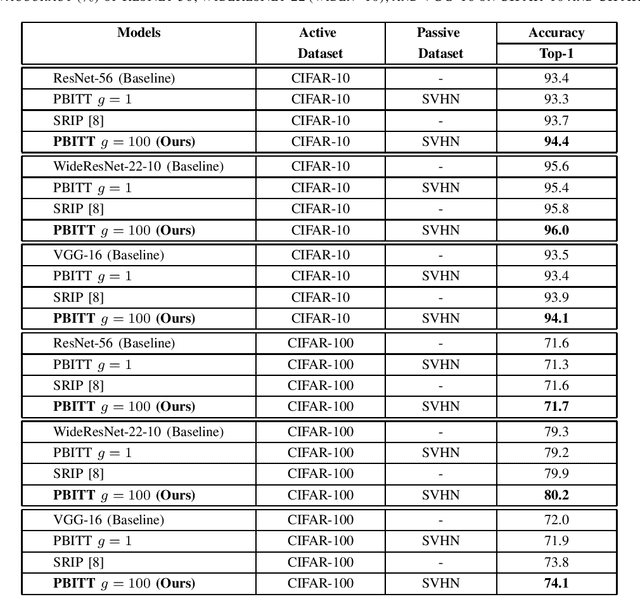

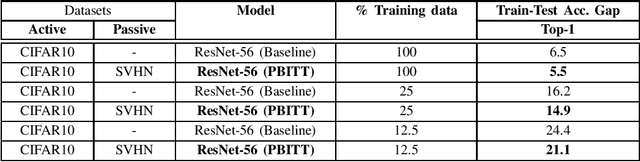
This work presents a novel training technique for deep neural networks that makes use of additional data from a distribution that is different from that of the original input data. This technique aims to reduce overfitting and improve the generalization performance of the network. Our proposed technique, namely Passive Batch Injection Training Technique (PBITT), even reduces the level of overfitting in networks that already use the standard techniques for reducing overfitting such as $L_2$ regularization and batch normalization, resulting in significant accuracy improvements. Passive Batch Injection Training Technique (PBITT) introduces a few passive mini-batches into the training process that contain data from a distribution that is different from the input data distribution. This technique does not increase the number of parameters in the final model and also does not increase the inference (test) time but still improves the performance of deep CNNs. To the best of our knowledge, this is the first work that makes use of different data distribution to aid the training of convolutional neural networks (CNNs). We thoroughly evaluate the proposed approach on standard architectures: VGG, ResNet, and WideResNet, and on several popular datasets: CIFAR-10, CIFAR-100, SVHN, and ImageNet. We observe consistent accuracy improvement by using the proposed technique. We also show experimentally that the model trained by our technique generalizes well to other tasks such as object detection on the MS-COCO dataset using Faster R-CNN. We present extensive ablations to validate the proposed approach. Our approach improves the accuracy of VGG-16 by a significant margin of 2.1% over the CIFAR-100 dataset.