 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal SGD With a Communication Overhead Depending Only on the Number of Workers
Paper and Code
Jun 03, 2020
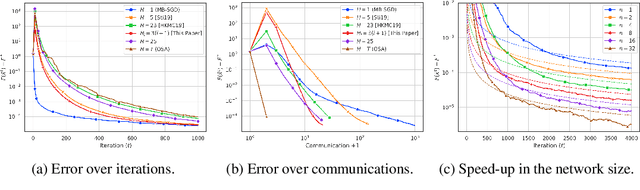
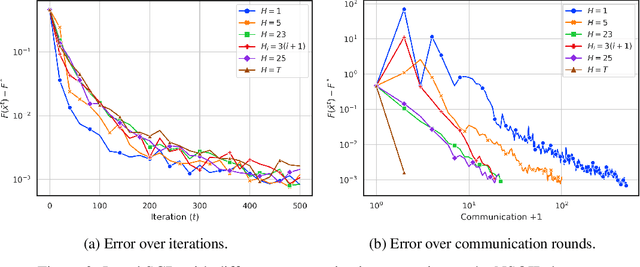
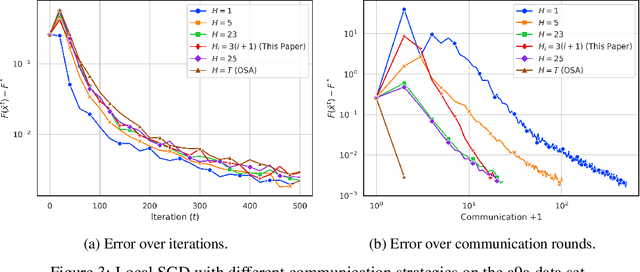
We consider speeding up stochastic gradient descent (SGD) by parallelizing it across multiple workers. We assume the same data set is shared among $n$ workers, who can take SGD steps and coordinate with a central server. Unfortunately, this could require a lot of communication between the workers and the server, which can dramatically reduce the gains from parallelism. The Local SGD method, proposed and analyzed in the earlier literature, suggests machines should make many local steps between such communications. While the initial analysis of Local SGD showed it needs $\Omega ( \sqrt{T} )$ communications for $T$ local gradient steps in order for the error to scale proportionately to $1/(nT)$, this has been successively improved in a string of papers, with the state-of-the-art requiring $\Omega \left( n \left( \mbox{ polynomial in log } (T) \right) \right)$ communications. In this paper, we give a new analysis of Local SGD. A consequence of our analysis is that Local SGD can achieve an error that scales as $1/(nT)$ with only a fixed number of communications independent of $T$: specifically, only $\Omega(n)$ communications are required.