 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance metrics for intervention-triggering prediction models do not reflect an expected reduction in outcomes from using the model
Paper and Code
Jun 02, 2020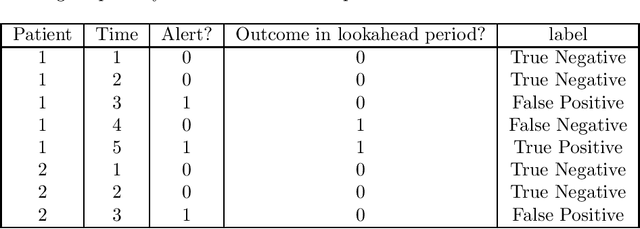


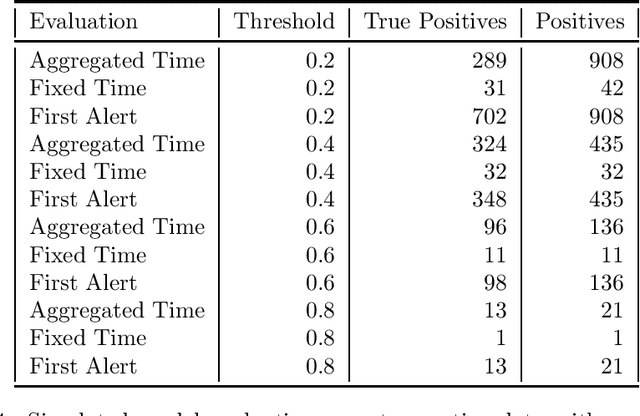
Clinical researchers often select among and evaluate risk prediction models using standard machine learning metrics based on confusion matrices. However, if these models are used to allocate interventions to patients, standard metrics calculated from retrospective data are only related to model utility (in terms of reductions in outcomes) under certain assumptions. When predictions are delivered repeatedly throughout time (e.g. in a patient encounter), the relationship between standard metrics and utility is further complicated. Several kinds of evaluations have been used in the literature, but it has not been clear what the target of estimation is in each evaluation. We synthesize these approaches, determine what is being estimated in each of them, and discuss under what assumptions those estimates are valid. We demonstrate our insights using simulated data as well as real data used in the design of an early warning system. Our theoretical and empirical results show that evaluations without interventional data either do not estimate meaningful quantities, require strong assumptions, or are limited to estimating best-case scenario bounds.