 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbation Analysis of Gradient-based Adversarial Attacks
Paper and Code
Jun 02, 2020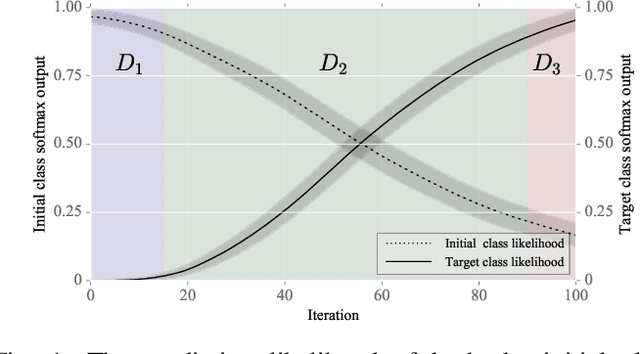
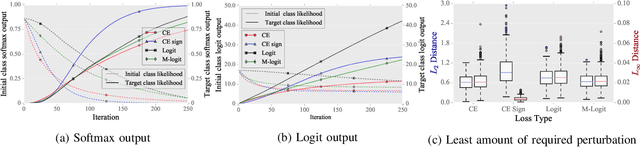
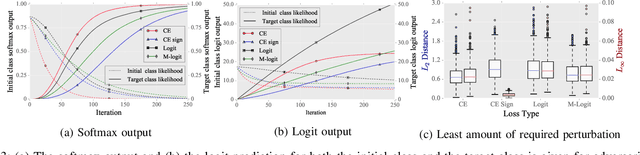
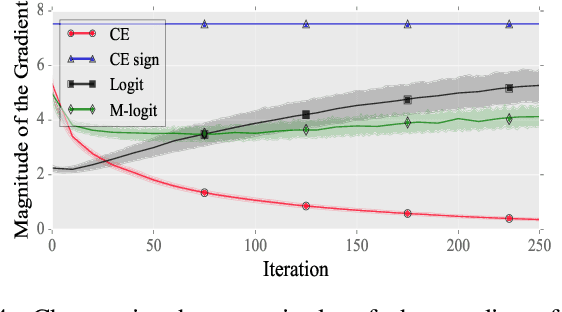
After the discovery of adversarial examples and their adverse effects on deep learning models, many studies focused on finding more diverse methods to generate these carefully crafted samples. Although empirical results on the effectiveness of adversarial example generation methods against defense mechanisms are discussed in detail in the literature, an in-depth study of the theoretical properties and the perturbation effectiveness of these adversarial attacks has largely been lacking. In this paper, we investigate the objective functions of three popular methods for adversarial example generation: the L-BFGS attack, the Iterative Fast Gradient Sign attack, and Carlini & Wagner's attack (CW). Specifically, we perform a comparative and formal analysis of the loss functions underlying the aforementioned attacks while laying out large-scale experimental results on ImageNet dataset. This analysis exposes (1) the faster optimization speed as well as the constrained optimization space of the cross-entropy loss, (2) the detrimental effects of using the signature of the cross-entropy loss on optimization precision as well as optimization space, and (3) the slow optimization speed of the logit loss in the context of adversariality. Our experiments reveal that the Iterative Fast Gradient Sign attack, which is thought to be fast for generating adversarial examples, is the worst attack in terms of the number of iterations required to create adversarial examples in the setting of equal perturbation. Moreover, our experiments show that the underlying loss function of CW, which is criticized for being substantially slower than other adversarial attacks, is not that much slower than other loss functions. Finally, we analyze how well neural networks can identify adversarial perturbations generated by the attacks under consideration, hereby revisiting the idea of adversarial retraining on ImageNet.