 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search with Reinforce and Masked Attention Autoregressive Density Estimators
Paper and Code
Jun 02, 2020
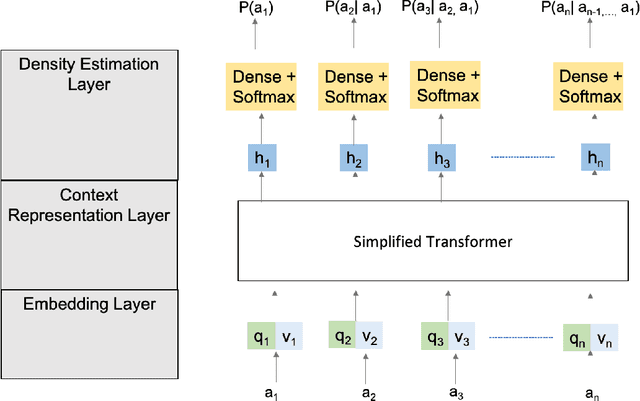
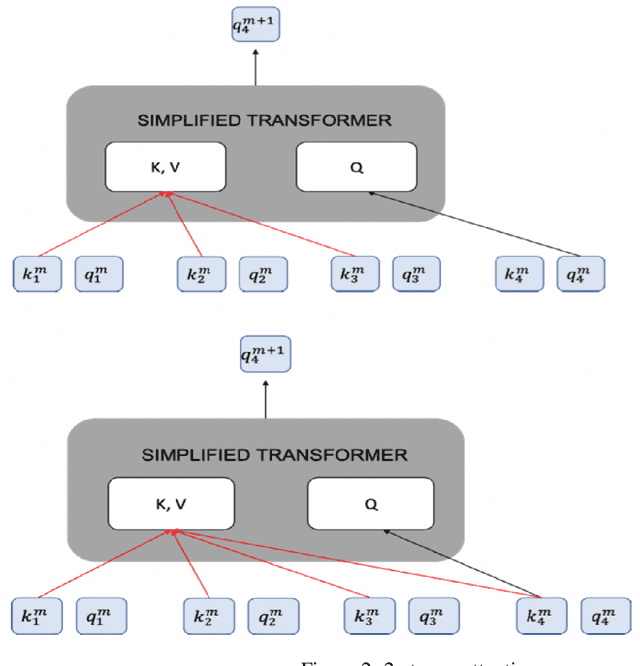

Neural Architecture Search has become a focus of the Machine Learning community. Techniques span Bayesian optimization with Gaussian priors, evolutionary learning, reinforcement learning based on policy gradient, Q-learning, and Monte-Carlo tree search. In this paper, we present a reinforcement learning algorithm based on policy gradient that uses an attention-based autoregressive model to design the policy network. We demonstrate how performance can be further improved by training an ensemble of policy networks with shared parameters, each network conditioned on a different autoregressive factorization order. On the NASBench-101 search space, it outperforms most algorithms in the literature, including random search. In particular, it outperforms RL methods based on policy gradients that use alternate architectures to specify the policy network, underscoring the importance of using masked attention in this setting. We have adhered to guidelines listed in Lindauer& Hutter (2019) while designing experiments and reporting results.