 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Matching for Low-Resource Classification
Paper and Code
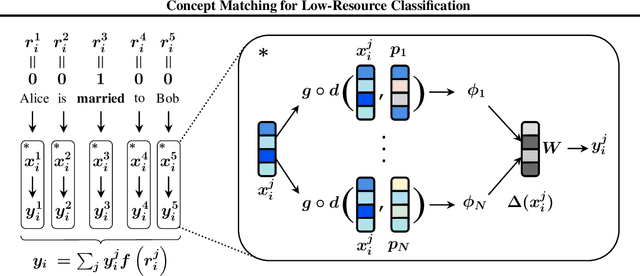


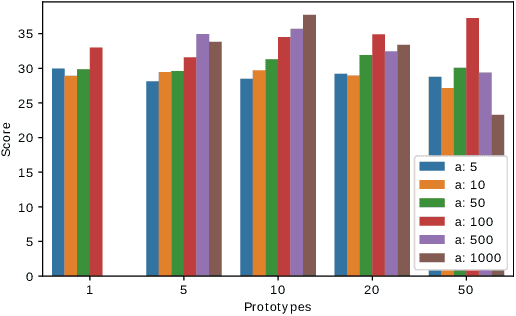
We propose a model to tackle classification tasks in the presence of very little training data. To this aim, we approximate the notion of exact match with a theoretically sound mechanism that computes a probability of matching in the input space. Importantly, the model learns to focus on elements of the input that are relevant for the task at hand; by leveraging highlighted portions of the training data, an error boosting technique guides the learning process. In practice, it increases the error associated with relevant parts of the input by a given factor. Remarkable results on text classification tasks confirm the benefits of the proposed approach in both balanced and unbalanced cases, thus being of practical use when labeling new examples is expensive. In addition, by inspecting its weights, it is often possible to gather insights on what the model has learned.