 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVGZSLNet: Audio-Visual Generalized Zero-Shot Learning by Reconstructing Label Features from Multi-Modal Embeddings
Paper and Code
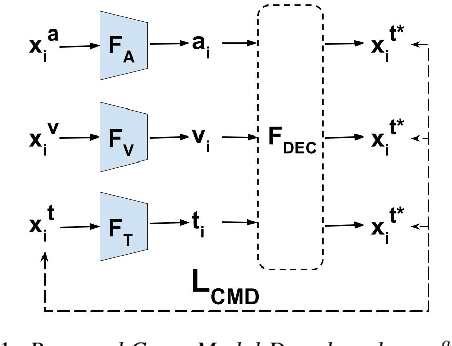
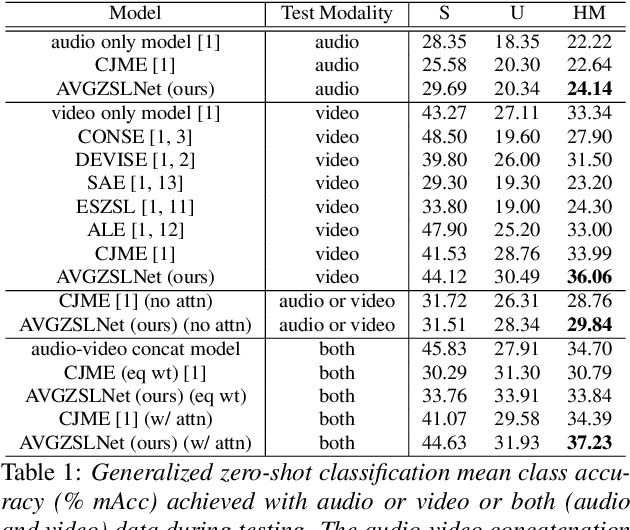
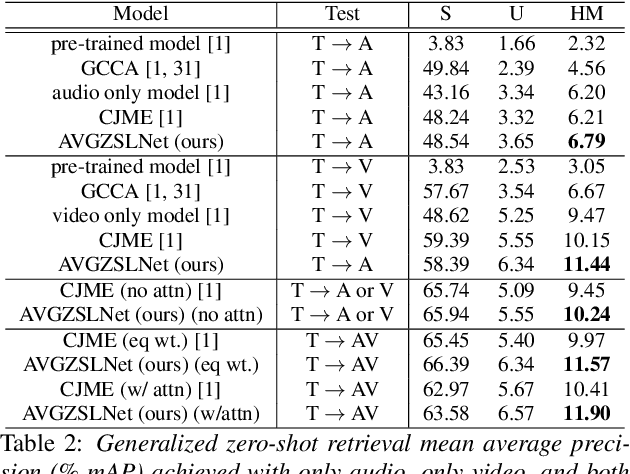

In this paper, we solve for the problem of generalized zero-shot learning in a multi-modal setting, where we have novel classes of audio/video during testing that were not seen during training. We demonstrate that projecting the audio and video embeddings to the class label text feature space allows us to use the semantic relatedness of text embeddings as a means for zero-shot learning. Importantly, our multi-modal zero-shot learning approach works even if a modality is missing at test time. Our approach makes use of a cross-modal decoder which enforces the constraint that the class label text features can be reconstructed from the audio and video embeddings of data points in order to perform better on the multi-modal zero-shot learning task. We further minimize the gap between audio and video embedding distributions using KL-Divergence loss. We test our approach on the zero-shot classification and retrieval tasks, and it performs better than other models in the presence of a single modality as well as in the presence of multiple modalities.