 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLOCS: Contrastive Learning of Cardiac Signals
Paper and Code

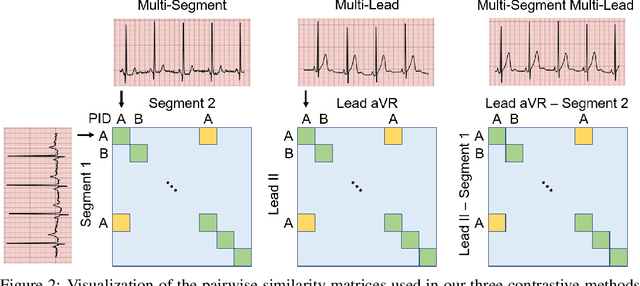
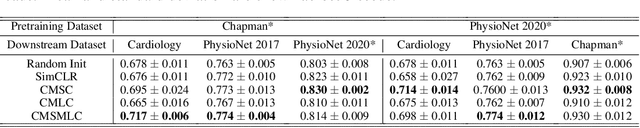
The healthcare industry generates troves of unlabelled physiological data. This data can be exploited via contrastive learning, a self-supervised pre-training mechanism that encourages representations of instances to be similar to one another. We propose a family of contrastive learning methods, CLOCS, that encourages representations across time, leads, and patients to be similar to one another. We show that CLOCS consistently outperforms the state-of-the-art approach, SimCLR, on both linear evaluation and fine-tuning downstream tasks. We also show that CLOCS achieves strong generalization performance with only 25% of labelled training data. Furthermore, our training procedure naturally generates patient-specific representations that can be used to quantify patient-similarity.