 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Layout-aware IE for Visually Rich Documents with Pre-trained Language Models
Paper and Code

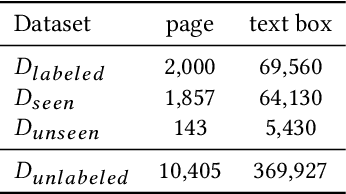
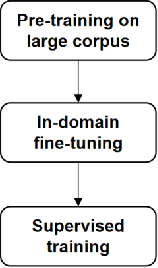
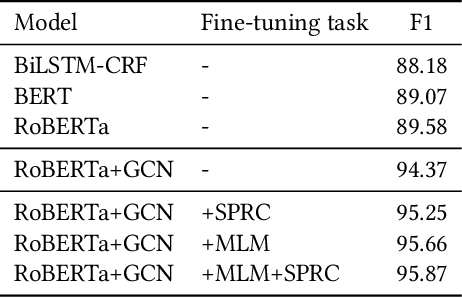
Many business documents processed in modern NLP and IR pipelines are visually rich: in addition to text, their semantics can also be captured by visual traits such as layout, format, and fonts. We study the problem of information extraction from visually rich documents (VRDs) and present a model that combines the power of large pre-trained language models and graph neural networks to efficiently encode both textual and visual information in business documents. We further introduce new fine-tuning objectives to improve in-domain unsupervised fine-tuning to better utilize large amount of unlabeled in-domain data. We experiment on real world invoice and resume data sets and show that the proposed method outperforms strong text-based RoBERTa baselines by 6.3% absolute F1 on invoices and 4.7% absolute F1 on resumes. When evaluated in a few-shot setting, our method requires up to 30x less annotation data than the baseline to achieve the same level of performance at ~90% F1.