 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconditional Audio Generation with Generative Adversarial Networks and Cycle Regularization
Paper and Code
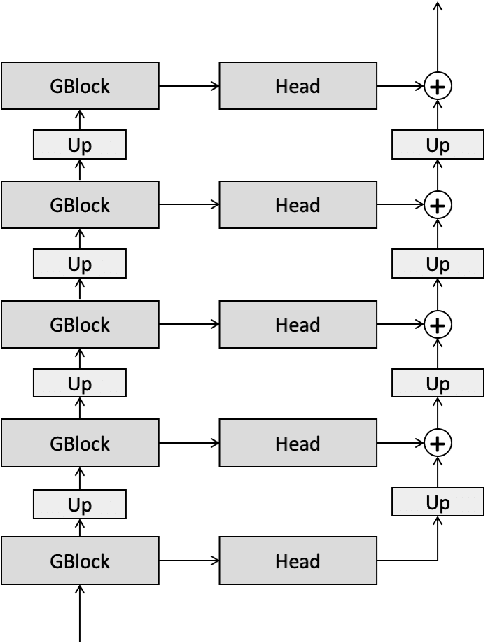
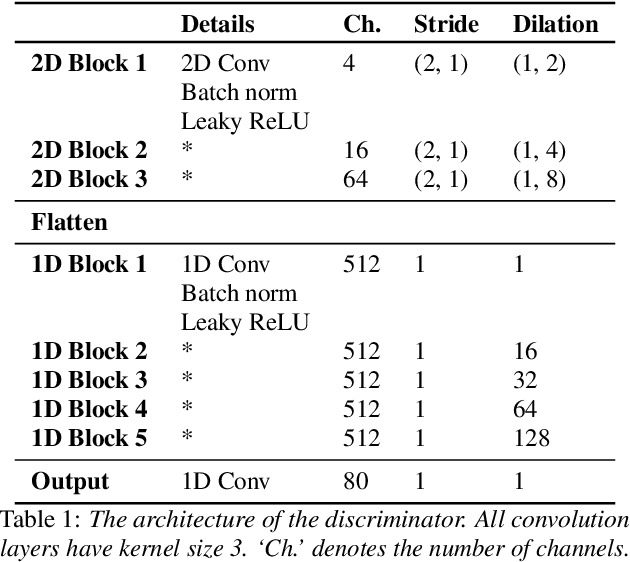
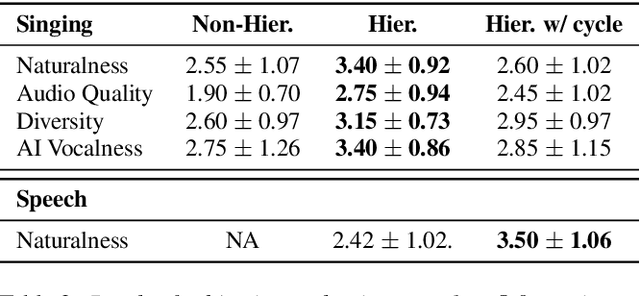
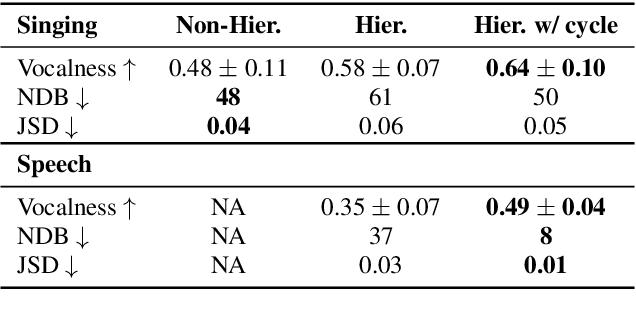
In a recent paper, we have presented a generative adversarial network (GAN)-based model for unconditional generation of the mel-spectrograms of singing voices. As the generator of the model is designed to take a variable-length sequence of noise vectors as input, it can generate mel-spectrograms of variable length. However, our previous listening test shows that the quality of the generated audio leaves room for improvement. The present paper extends and expands that previous work in the following aspects. First, we employ a hierarchical architecture in the generator to induce some structure in the temporal dimension. Second, we introduce a cycle regularization mechanism to the generator to avoid mode collapse. Third, we evaluate the performance of the new model not only for generating singing voices, but also for generating speech voices. Evaluation result shows that new model outperforms the prior one both objectively and subjectively. We also employ the model to unconditionally generate sequences of piano and violin music and find the result promising. Audio examples, as well as the code for implementing our model, will be publicly available online upon paper publication.