 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deeper Look at the Unsupervised Learning of Disentangled Representations in $β$-VAE from the Perspective of Core Object Recognition
Paper and Code
Apr 25, 2020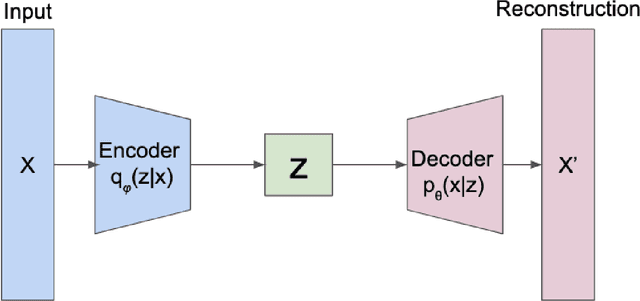
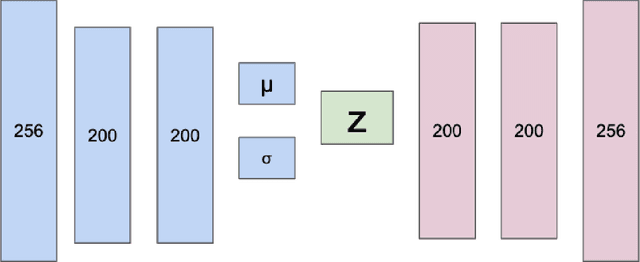
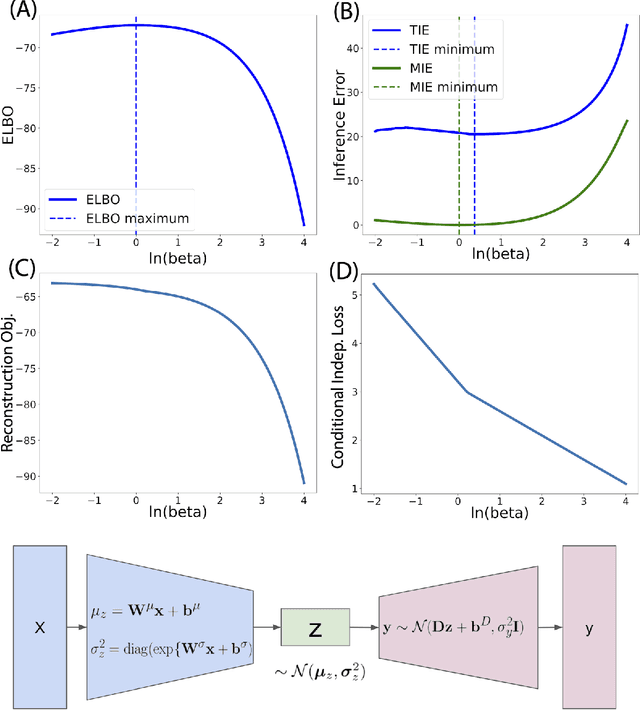
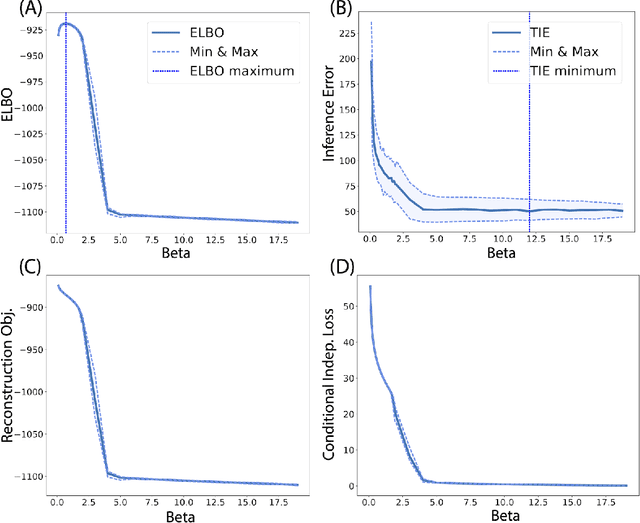
The ability to recognize objects despite there being differences in appearance, known as Core Object Recognition, forms a critical part of human perception. While it is understood that the brain accomplishes Core Object Recognition through feedforward, hierarchical computations through the visual stream, the underlying algorithms that allow for invariant representations to form downstream is still not well understood. (DiCarlo et al., 2012) Various computational perceptual models have been built to attempt and tackle the object identification task in an artificial perceptual setting. Artificial Neural Networks, computational graphs consisting of weighted edges and mathematical operations at vertices, are loosely inspired by neural networks in the brain and have proven effective at various visual perceptual tasks, including object characterization and identification. (Pinto et al., 2008) (DiCarlo et al., 2012) For many data analysis tasks, learning representations where each dimension is statistically independent and thus disentangled from the others is useful. If the underlying generative factors of the data are also statistically independent, Bayesian inference of latent variables can form disentangled representations. This thesis constitutes a research project exploring a generalization of the Variational Autoencoder (VAE), $\beta$-VAE, that aims to learn disentangled representations using variational inference. $\beta$-VAE incorporates the hyperparameter $\beta$, and enforces conditional independence of its bottleneck neurons, which is in general not compatible with the statistical independence of latent variables. This text examines this architecture, and provides analytical and numerical arguments, with the goal of demonstrating that this incompatibility leads to a non-monotonic inference performance in $\beta$-VAE with a finite optimal $\beta$.