 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixML: A Unified Analysis of Weakly Consistent Parallel Learning
Paper and Code
Jun 06, 2020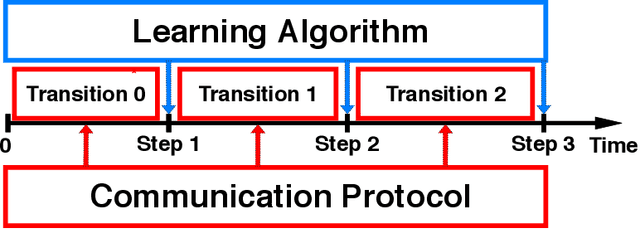
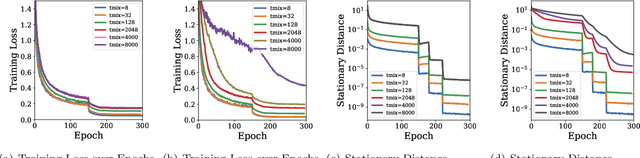
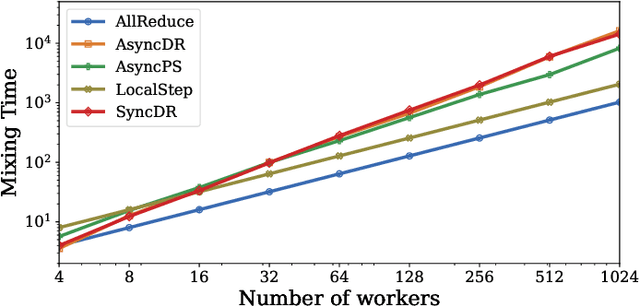
Parallelism is a ubiquitous method for accelerating machine learning algorithms. However, theoretical analysis of parallel learning is usually done in an algorithm- and protocol-specific setting, giving little insight about how changes in the structure of communication could affect convergence. In this paper we propose MixML, a general framework for analyzing convergence of weakly consistent parallel machine learning. Our framework includes: (1) a unified way of modeling the communication process among parallel workers; (2) a new parameter, the mixing time tmix, that quantifies how the communication process affects convergence; and (3) a principled way of converting a convergence proof for a sequential algorithm into one for a parallel version that depends only on tmix. We show MixML recovers and improves on known convergence bounds for asynchronous and/or decentralized versions of many algorithms, includingSGD and AMSGrad. Our experiments substantiate the theory and show the dependency of convergence on the underlying mixing time.