 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models for Generic Light Field Reconstruction
Paper and Code
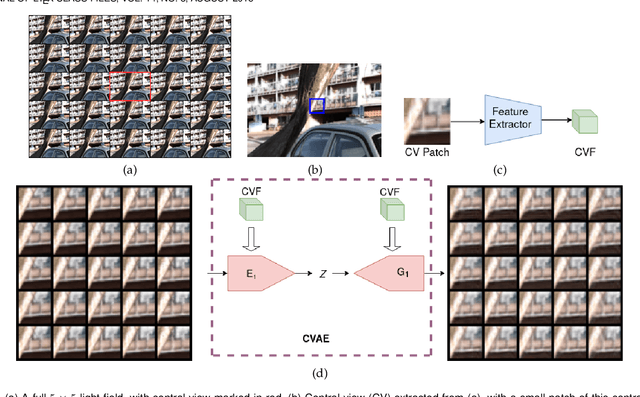
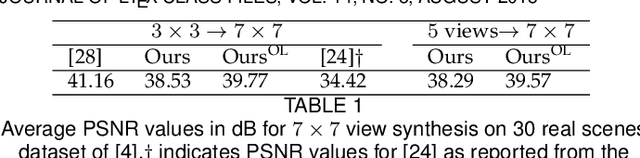
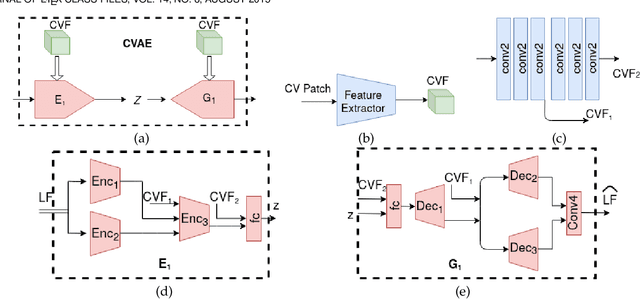
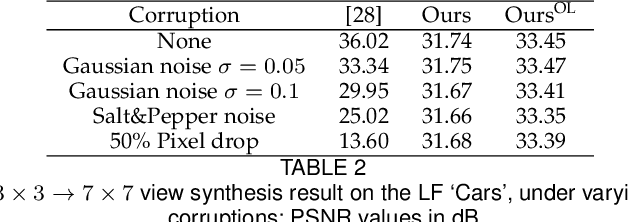
Recently deep generative models have achieved impressive progress in modeling the distribution of training data. In this work, we present for the first time generative models for 4D light field patches using variational autoencoders to capture the data distribution of light field patches. We develop two generative models, a model conditioned on the central view of the light field and an unconditional model. We incorporate our generative priors in an energy minimization framework to address diverse light field reconstruction tasks. While pure learning-based approaches do achieve excellent results on each instance of such a problem, their applicability is limited to the specific observation model they have been trained on. On the contrary, our trained light field generative models can be incorporated as a prior into any model-based optimization approach and therefore extend to diverse reconstruction tasks including light field view synthesis, spatial-angular super resolution and reconstruction from coded projections. Our proposed method demonstrates good reconstruction, with performance approaching end-to-end trained networks, while outperforming traditional model-based approaches on both synthetic and real scenes. Furthermore, we show that our approach enables reliable light field recovery despite distortions in the input.