 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Algorithmic Efficiency of Neural Networks
Paper and Code
May 08, 2020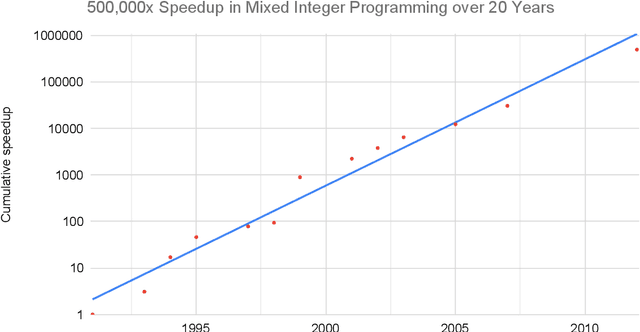
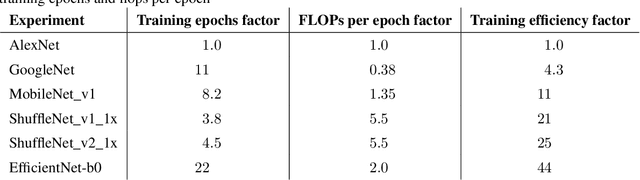
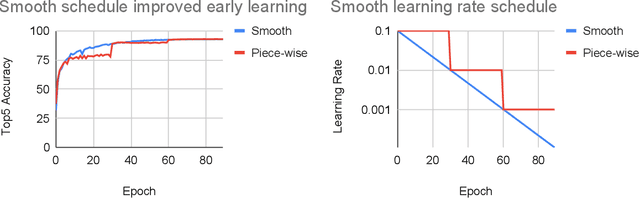
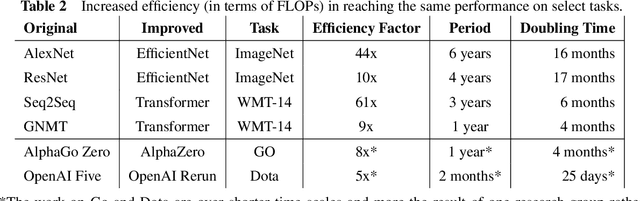
Three factors drive the advance of AI: algorithmic innovation, data, and the amount of compute available for training. Algorithmic progress has traditionally been more difficult to quantify than compute and data. In this work, we argue that algorithmic progress has an aspect that is both straightforward to measure and interesting: reductions over time in the compute needed to reach past capabilities. We show that the number of floating-point operations required to train a classifier to AlexNet-level performance on ImageNet has decreased by a factor of 44x between 2012 and 2019. This corresponds to algorithmic efficiency doubling every 16 months over a period of 7 years. By contrast, Moore's Law would only have yielded an 11x cost improvement. We observe that hardware and algorithmic efficiency gains multiply and can be on a similar scale over meaningful horizons, which suggests that a good model of AI progress should integrate measures from both.