 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Accurate Emulators for Scientific Processes using Calibration-Driven Deep Models
Paper and Code
May 05, 2020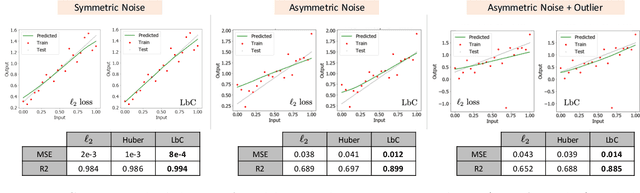
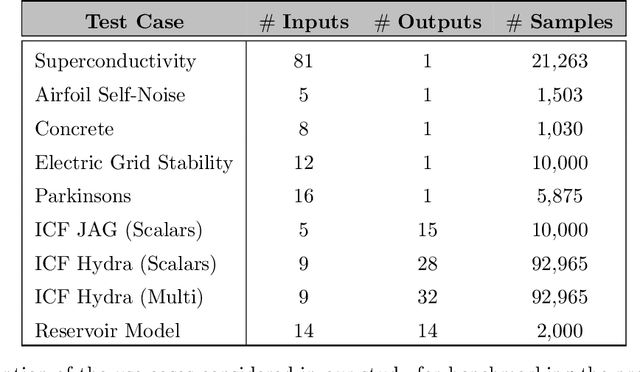
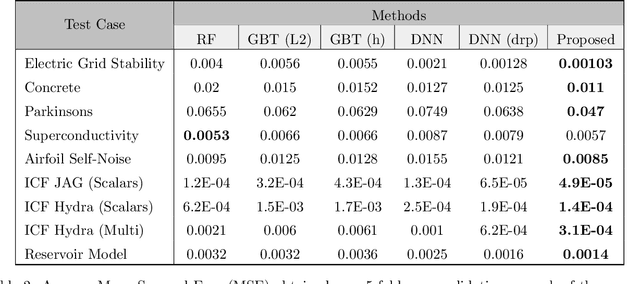
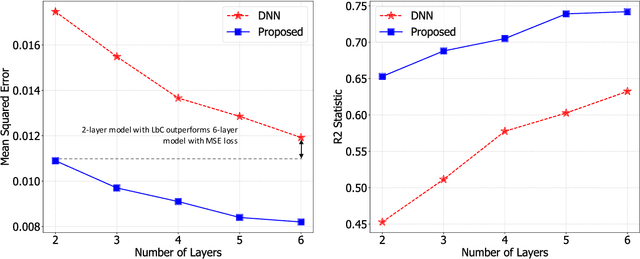
Predictive models that accurately emulate complex scientific processes can achieve exponential speed-ups over numerical simulators or experiments, and at the same time provide surrogates for improving the subsequent analysis. Consequently, there is a recent surge in utilizing modern machine learning (ML) methods, such as deep neural networks, to build data-driven emulators. While the majority of existing efforts has focused on tailoring off-the-shelf ML solutions to better suit the scientific problem at hand, we study an often overlooked, yet important, problem of choosing loss functions to measure the discrepancy between observed data and the predictions from a model. Due to lack of better priors on the expected residual structure, in practice, simple choices such as the mean squared error and the mean absolute error are made. However, the inherent symmetric noise assumption made by these loss functions makes them inappropriate in cases where the data is heterogeneous or when the noise distribution is asymmetric. We propose Learn-by-Calibrating (LbC), a novel deep learning approach based on interval calibration for designing emulators in scientific applications, that are effective even with heterogeneous data and are robust to outliers. Using a large suite of use-cases, we show that LbC provides significant improvements in generalization error over widely-adopted loss function choices, achieves high-quality emulators even in small data regimes and more importantly, recovers the inherent noise structure without any explicit priors.