 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Entities and Topics from News and Connecting Criminal Records
Paper and Code
May 03, 2020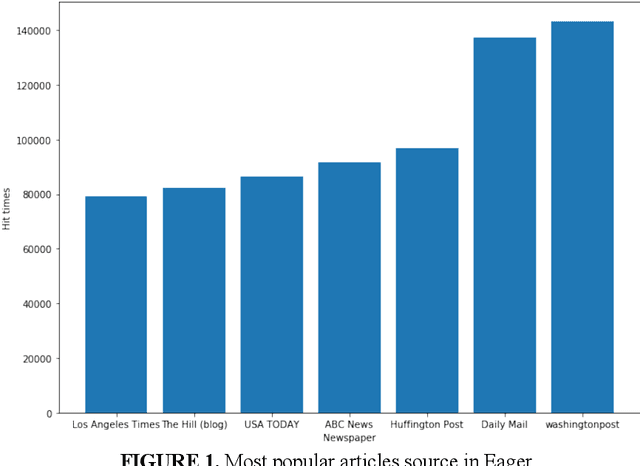
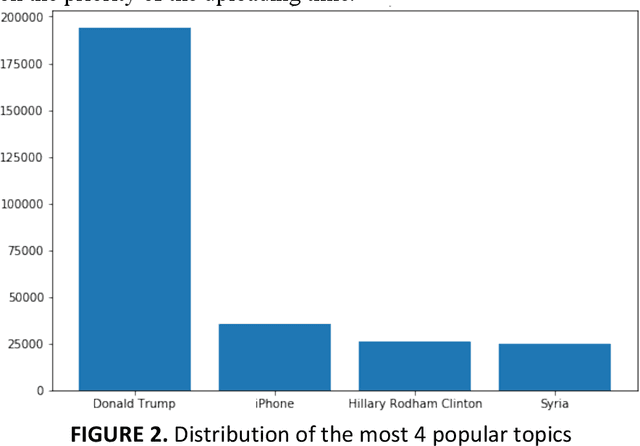
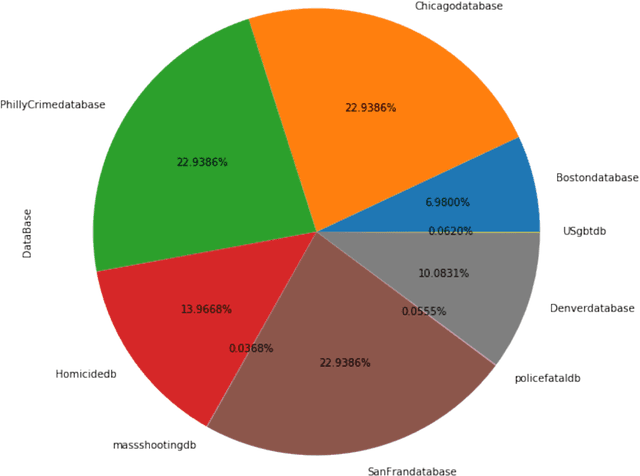
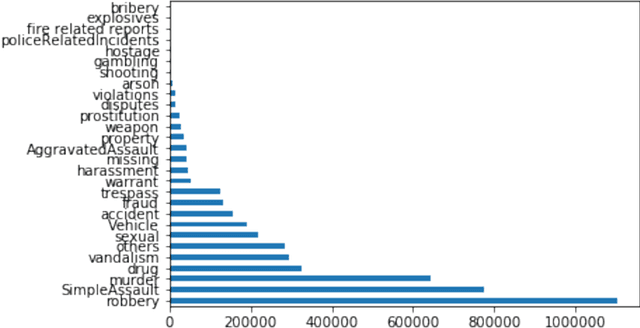
The goal of this paper is to summarize methodologies used in extracting entities and topics from a database of criminal records and from a database of newspapers. Statistical models had successfully been used in studying the topics of roughly 300,000 New York Times articles. In addition, these models had also been used to successfully analyze entities related to people, organizations, and places (D Newman, 2006). Additionally, analytical approaches, especially in hotspot mapping, were used in some researches with an aim to predict crime locations and circumstances in the future, and those approaches had been tested quite successfully (S Chainey, 2008). Based on the two above notions, this research was performed with the intention to apply data science techniques in analyzing a big amount of data, selecting valuable intelligence, clustering violations depending on their types of crime, and creating a crime graph that changes through time. In this research, the task was to download criminal datasets from Kaggle and a collection of news articles from Kaggle and EAGER project databases, and then to merge these datasets into one general dataset. The most important goal of this project was performing statistical and natural language processing methods to extract entities and topics as well as to group similar data points into correct clusters, in order to understand public data about U.S related crimes better.