 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Table Extractor : A Framework for Joint Table Identification and Cell Structure Recognition Using Visual Context
Paper and Code
May 01, 2020
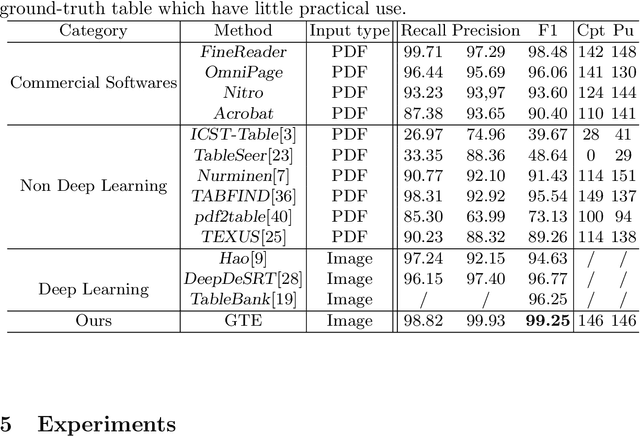
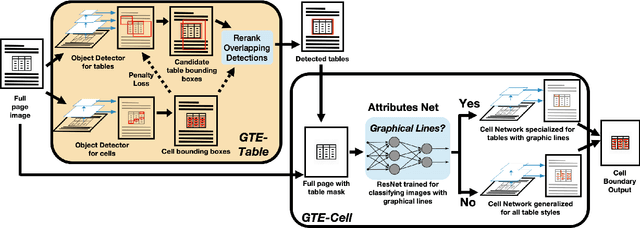

Documents are often the format of choice for knowledge sharing and preservation in business and science. Much of the critical data are captured in tables. Unfortunately, most documents are stored and distributed in PDF or scanned images, which fail to preserve table formatting. Recent vision-based deep learning approaches have been proposed to address this gap, but most still cannot achieve state-of-the-art results. We present Global Table Extractor (GTE), a vision-guided systematic framework for joint table detection and cell structured recognition, which could be built on top of any object detection model. With GTE-Table, we invent a new penalty based on the natural cell containment constraint of tables to train our table network aided by cell location predictions. GTE-Cell is a new hierarchical cell detection network that leverages table styles. Further, we design a method to automatically label table and cell structure in existing documents to cheaply create a large corpus of training and test data. We use this to create SD-tables and SEC-tables, real world and complex scientific and financial datasets with detailed table structure annotations to help train and test structure recognition. Our deep learning framework surpasses previous state-of-the-art results on the ICDAR 2013 table competition test dataset in both table detection and cell structure recognition, with a significant 6.8% improvement in the full table extraction system. We also show more than 30% improvement in cell structure recognition F1-score when compared to a vanilla RetinaNet object detection model in our out-of-domain financial dataset (SEC-Tables).