 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Integration of Disentangled Attended Expression and Identity FeaturesFor Facial Expression Transfer andSynthesis
Paper and Code
May 01, 2020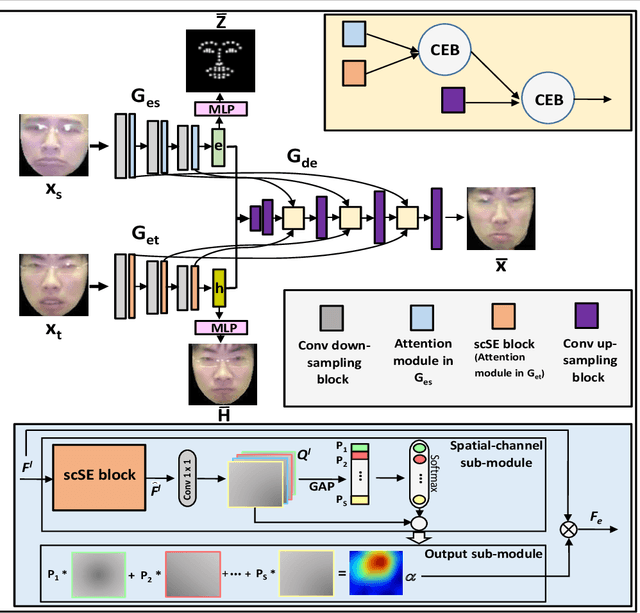
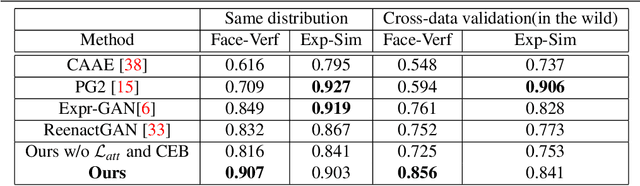

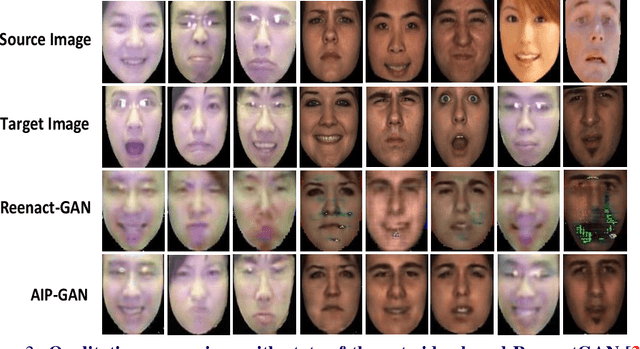
In this paper, we present an Attention-based Identity Preserving Generative Adversarial Network (AIP-GAN) to overcome the identity leakage problem from a source image to a generated face image, an issue that is encountered in a cross-subject facial expression transfer and synthesis process. Our key insight is that the identity preserving network should be able to disentangle and compose shape, appearance, and expression information for efficient facial expression transfer and synthesis. Specifically, the expression encoder of our AIP-GAN disentangles the expression information from the input source image by predicting its facial landmarks using our supervised spatial and channel-wise attention module. Similarly, the disentangled expression-agnostic identity features are extracted from the input target image by inferring its combined intrinsic-shape and appearance image employing our self-supervised spatial and channel-wise attention mod-ule. To leverage the expression and identity information encoded by the intermediate layers of both of our encoders, we combine these features with the features learned by the intermediate layers of our decoder using a cross-encoder bilinear pooling operation. Experimental results show the promising performance of our AIP-GAN based technique.