 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing the Testing Error without a Testing Set
Paper and Code
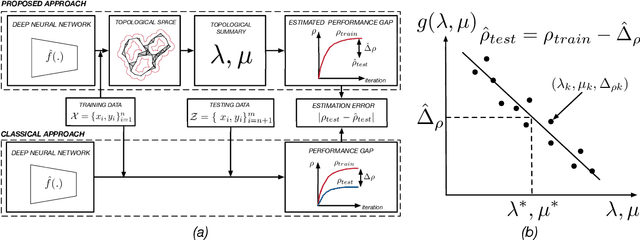

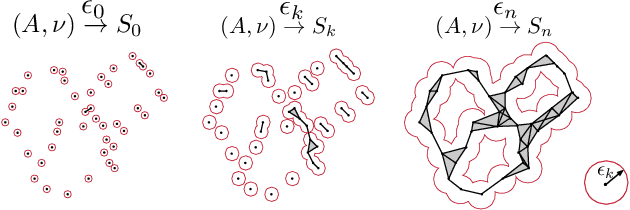
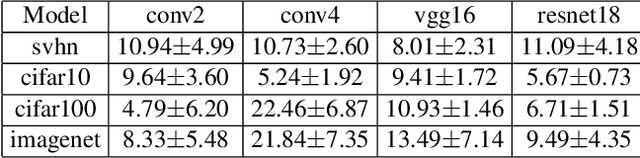
Deep Neural Networks (DNNs) have revolutionized computer vision. We now have DNNs that achieve top (performance) results in many problems, including object recognition, facial expression analysis, and semantic segmentation, to name but a few. The design of the DNNs that achieve top results is, however, non-trivial and mostly done by trail-and-error. That is, typically, researchers will derive many DNN architectures (i.e., topologies) and then test them on multiple datasets. However, there are no guarantees that the selected DNN will perform well in the real world. One can use a testing set to estimate the performance gap between the training and testing sets, but avoiding overfitting-to-the-testing-data is almost impossible. Using a sequestered testing dataset may address this problem, but this requires a constant update of the dataset, a very expensive venture. Here, we derive an algorithm to estimate the performance gap between training and testing that does not require any testing dataset. Specifically, we derive a number of persistent topology measures that identify when a DNN is learning to generalize to unseen samples. This allows us to compute the DNN's testing error on unseen samples, even when we do not have access to them. We provide extensive experimental validation on multiple networks and datasets to demonstrate the feasibility of the proposed approach.