 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Word Embeddings and N-grams for Unsupervised Document Summarization
Paper and Code
Apr 25, 2020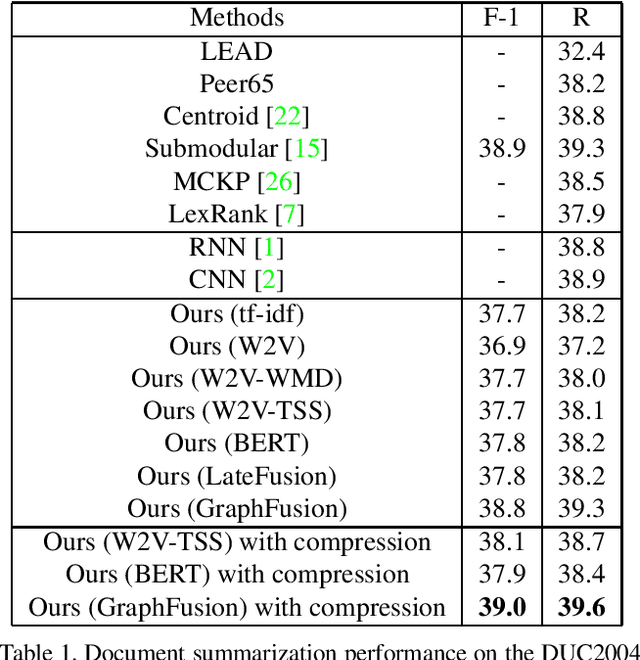
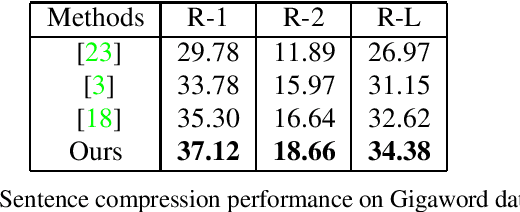
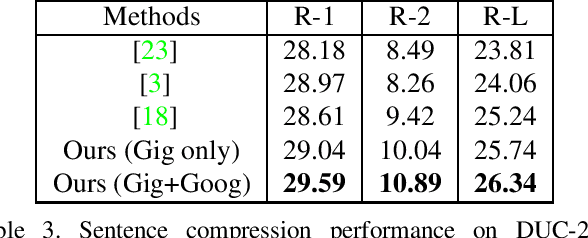
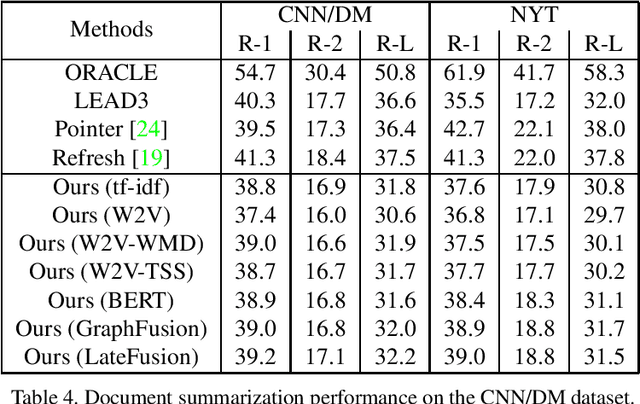
Graph-based extractive document summarization relies on the quality of the sentence similarity graph. Bag-of-words or tf-idf based sentence similarity uses exact word matching, but fails to measure the semantic similarity between individual words or to consider the semantic structure of sentences. In order to improve the similarity measure between sentences, we employ off-the-shelf deep embedding features and tf-idf features, and introduce a new text similarity metric. An improved sentence similarity graph is built and used in a submodular objective function for extractive summarization, which consists of a weighted coverage term and a diversity term. A Transformer based compression model is developed for sentence compression to aid in document summarization. Our summarization approach is extractive and unsupervised. Experiments demonstrate that our approach can outperform the tf-idf based approach and achieve state-of-the-art performance on the DUC04 dataset, and comparable performance to the fully supervised learning methods on the CNN/DM and NYT datasets.