 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Features for Kernel Approximation: A Survey in Algorithms, Theory, and Beyond
Paper and Code
Apr 24, 2020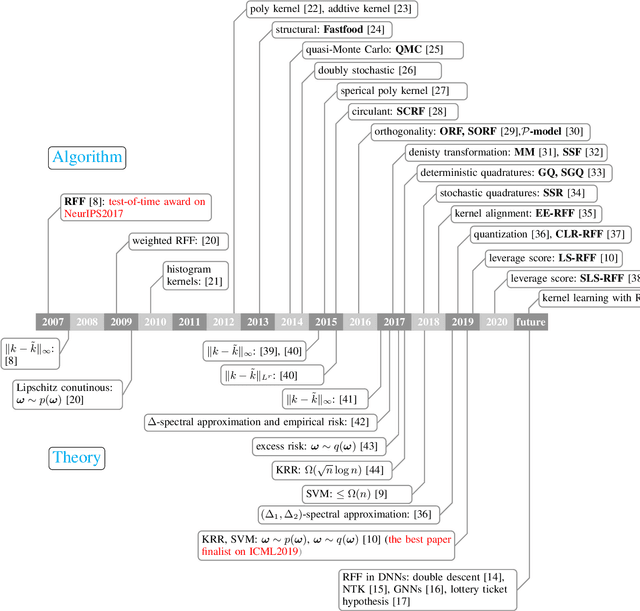
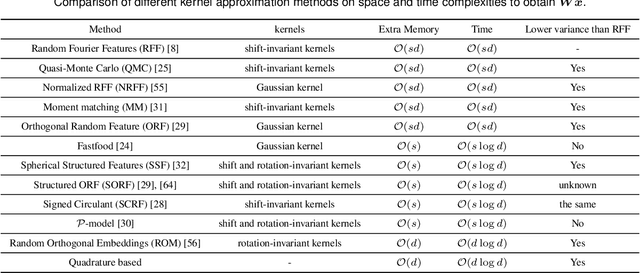


Random features is one of the most sought-after research topics in statistical machine learning to speed up kernel methods in large-scale situations. Related works have won the NeurIPS test-of-time award in 2017 and the ICML best paper finalist in 2019. However, comprehensive studies on this topic seem to be missing, which results in different, sometimes conflicting, statements. In this survey, we attempt to throughout and systematically review the past ten years work on random features regarding to algorithmic and theoretical aspects. First, the fundamental characteristics, primary motivations, and contributions of representative random features based algorithms are summarized according to their sampling scheme, learning procedure, variance reduction, and exploitation of training data. Second, we review theoretical results of random features to answer the key question: how many random features are needed to ensure a high approximation quality or no loss of empirical risk and expected risk in a learning estimator. Third, popular random features based algorithms are comprehensively evaluated on several large scale benchmark datasets on the approximation quality and the prediction performance for classification and regression. Last, we link random features to current over-parameterized deep neural networks (DNNs) by investigating their relationships, the usage of random features to analysis over-parameterized networks, and the gap in the current theoretical results. As a result, this survey could be a gentle use guide for practitioners to follow this topic, apply representative algorithms, and grasp theoretical results under various technical assumptions. We think that this survey helps to facilitate a discussion on ongoing issues for this topic, and specifically, it sheds light on promising research directions.