 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Scaling Law from the Dimension of the Data Manifold
Paper and Code
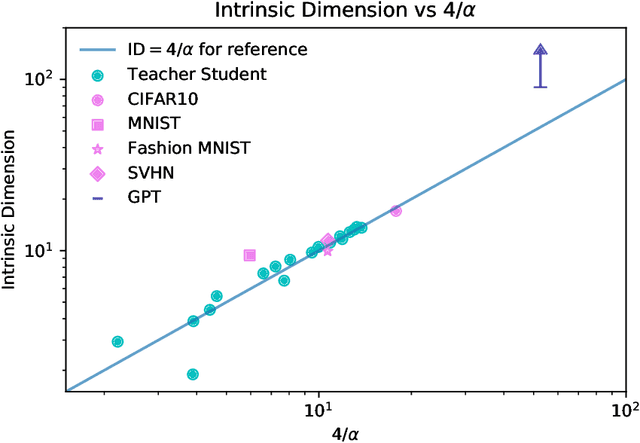
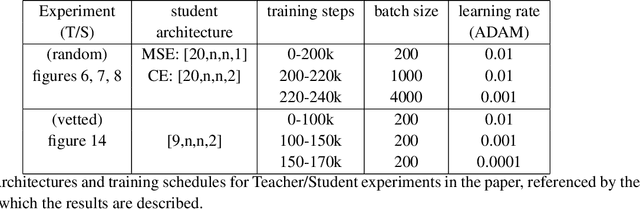
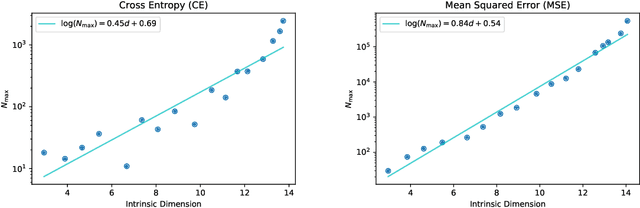
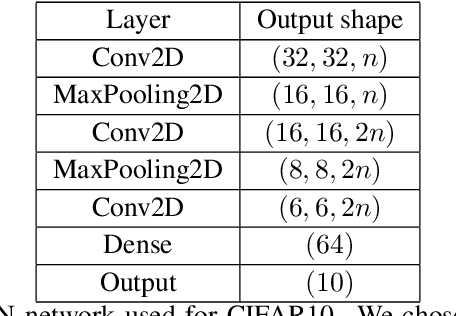
When data is plentiful, the loss achieved by well-trained neural networks scales as a power-law $L \propto N^{-\alpha}$ in the number of network parameters $N$. This empirical scaling law holds for a wide variety of data modalities, and may persist over many orders of magnitude. The scaling law can be explained if neural models are effectively just performing regression on a data manifold of intrinsic dimension $d$. This simple theory predicts that the scaling exponents $\alpha \approx 4/d$ for cross-entropy and mean-squared error losses. We confirm the theory by independently measuring the intrinsic dimension and the scaling exponents in a teacher/student framework, where we can study a variety of $d$ and $\alpha$ by dialing the properties of random teacher networks. We also test the theory with CNN image classifiers on several datasets and with GPT-type language models.