 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Entity Enrichment by Leveraging Multilingual Descriptions for Link Prediction
Paper and Code

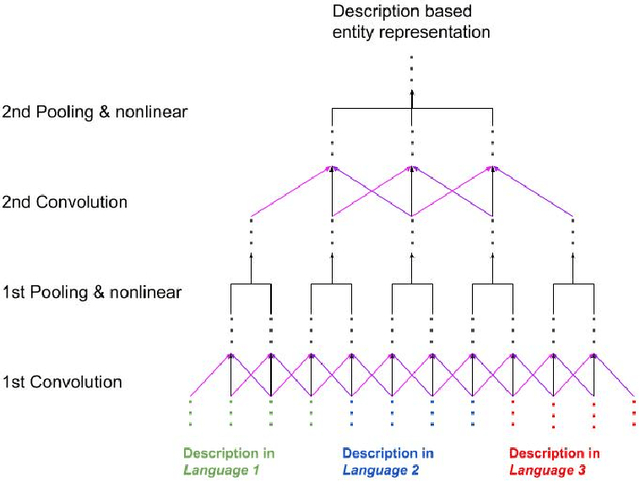
Most Knowledge Graphs (KGs) contain textual descriptions of entities in various natural languages. These descriptions of entities provide valuable information that may not be explicitly represented in the structured part of the KG. Based on this fact, some link prediction methods which make use of the information presented in the textual descriptions of entities have been proposed to learn representations of (monolingual) KGs. However, these methods use entity descriptions in only one language and ignore the fact that descriptions given in different languages may provide complementary information and thereby also additional semantics. In this position paper, the problem of effectively leveraging multilingual entity descriptions for the purpose of link prediction in KGs will be discussed along with potential solutions to the problem.