 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantized Contrastive Predictive Coding for Template-based Music Generation
Paper and Code
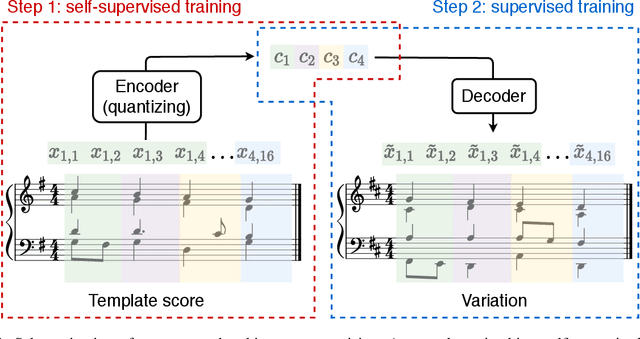
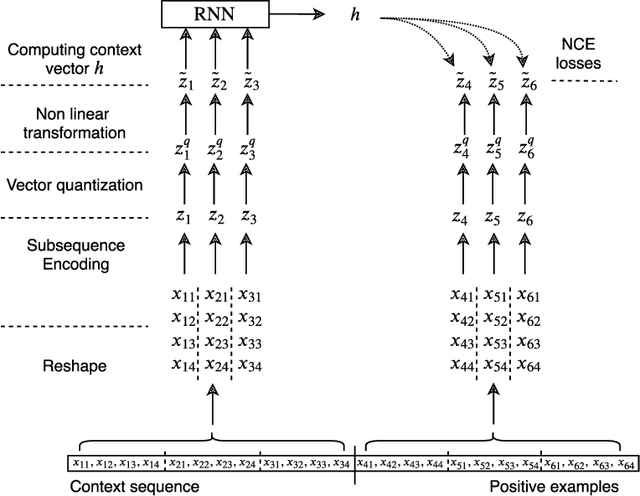
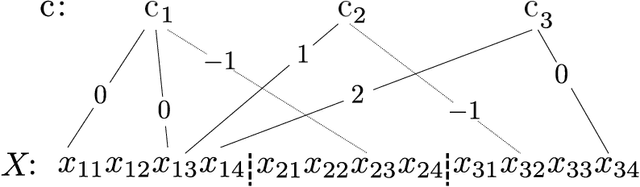

In this work, we propose a flexible method for generating variations of discrete sequences in which tokens can be grouped into basic units, like sentences in a text or bars in music. More precisely, given a template sequence, we aim at producing novel sequences sharing perceptible similarities with the original template without relying on any annotation; so our problem of generating variations is intimately linked to the problem of learning relevant high-level representations without supervision. Our contribution is two-fold: First, we propose a self-supervised encoding technique, named Vector Quantized Contrastive Predictive Coding which allows to learn a meaningful assignment of the basic units over a discrete set of codes, together with mechanisms allowing to control the information content of these learnt discrete representations. Secondly, we show how these compressed representations can be used to generate variations of a template sequence by using an appropriate attention pattern in the Transformer architecture. We illustrate our approach on the corpus of J.S. Bach chorales where we discuss the musical meaning of the learnt discrete codes and show that our proposed method allows to generate coherent and high-quality variations of a given template.