 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPCNet:Spatial Preserve and Content-aware Network for Human Pose Estimation
Paper and Code
Apr 13, 2020
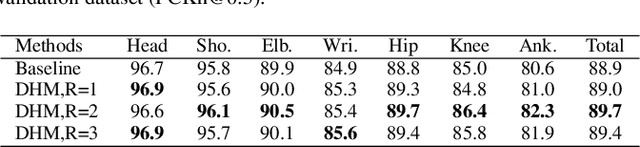
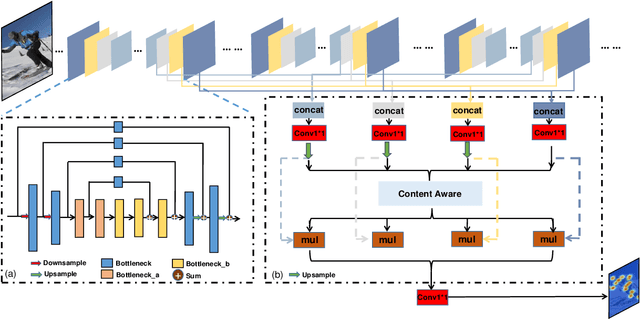
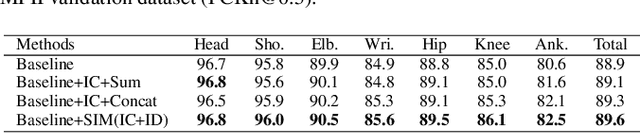
Human pose estimation is a fundamental yet challenging task in computer vision. Although deep learning techniques have made great progress in this area, difficult scenarios (e.g., invisible keypoints, occlusions, complex multi-person scenarios, and abnormal poses) are still not well-handled. To alleviate these issues, we propose a novel Spatial Preserve and Content-aware Network(SPCNet), which includes two effective modules: Dilated Hourglass Module(DHM) and Selective Information Module(SIM). By using the Dilated Hourglass Module, we can preserve the spatial resolution along with large receptive field. Similar to Hourglass Network, we stack the DHMs to get the multi-stage and multi-scale information. Then, a Selective Information Module is designed to select relatively important features from different levels under a sufficient consideration of spatial content-aware mechanism and thus considerably improves the performance. Extensive experiments on MPII, LSP and FLIC human pose estimation benchmarks demonstrate the effectiveness of our network. In particular, we exceed previous methods and achieve the state-of-the-art performance on three aforementioned benchmark datasets.