 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-based Regularization of VAE Latent Spaces
Paper and Code
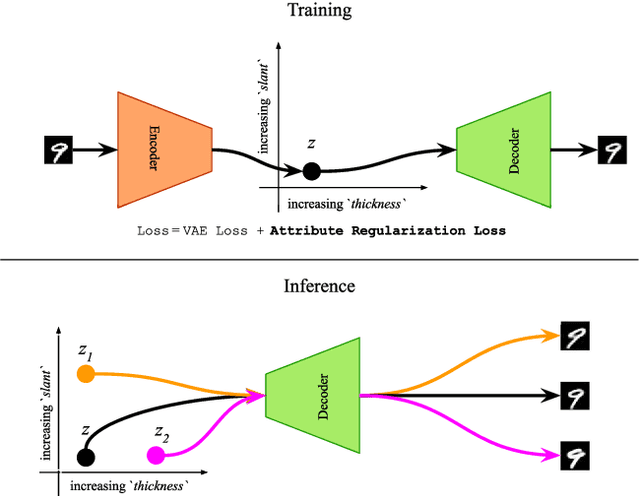


Selective manipulation of data attributes using deep generative models is an active area of research. In this paper, we present a novel method to structure the latent space of a Variational Auto-Encoder (VAE) to encode different continuous-valued attributes explicitly. This is accomplished by using an attribute regularization loss which enforces a monotonic relationship between the attribute values and the latent code of the dimension along which the attribute is to be encoded. Consequently, post-training, the model can be used to manipulate the attribute by simply changing the latent code of the corresponding regularized dimension. The results obtained from several quantitative and qualitative experiments show that the proposed method leads to disentangled and interpretable latent spaces that can be used to effectively manipulate a wide range of data attributes spanning image and symbolic music domains.