 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirrorNet: A Deep Bayesian Approach to Reflective 2D Pose Estimation from Human Images
Paper and Code
Apr 08, 2020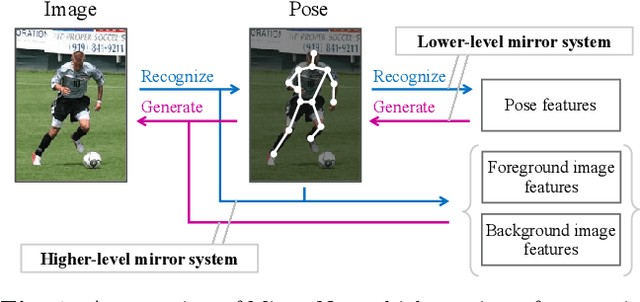

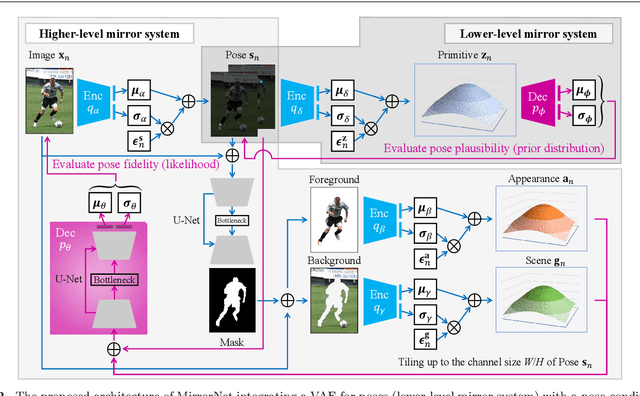
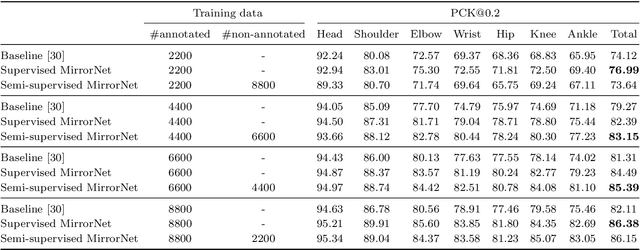
This paper proposes a statistical approach to 2D pose estimation from human images. The main problems with the standard supervised approach, which is based on a deep recognition (image-to-pose) model, are that it often yields anatomically implausible poses, and its performance is limited by the amount of paired data. To solve these problems, we propose a semi-supervised method that can make effective use of images with and without pose annotations. Specifically, we formulate a hierarchical generative model of poses and images by integrating a deep generative model of poses from pose features with that of images from poses and image features. We then introduce a deep recognition model that infers poses from images. Given images as observed data, these models can be trained jointly in a hierarchical variational autoencoding (image-to-pose-to-feature-to-pose-to-image) manner. The results of experiments show that the proposed reflective architecture makes estimated poses anatomically plausible, and the performance of pose estimation improved by integrating the recognition and generative models and also by feeding non-annotated images.