 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural language processing for word sense disambiguation and information extraction
Paper and Code
Apr 05, 2020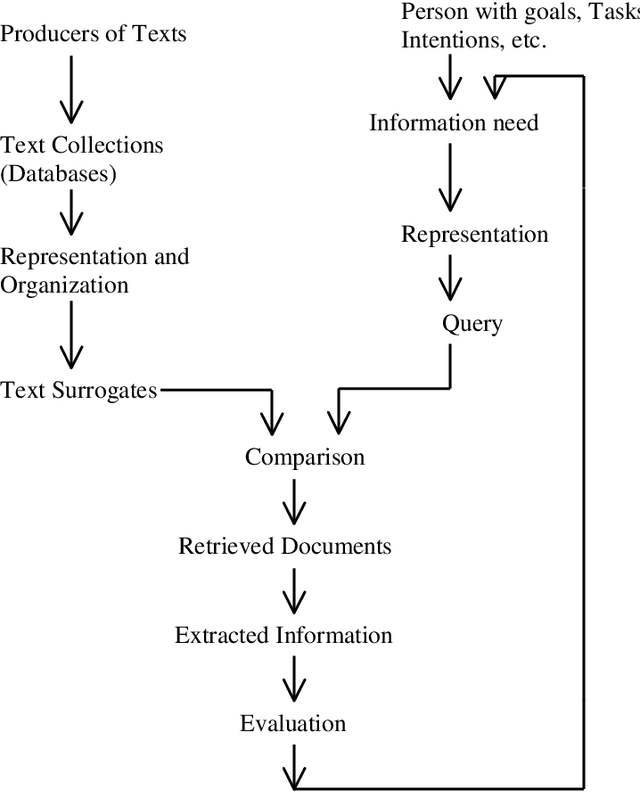
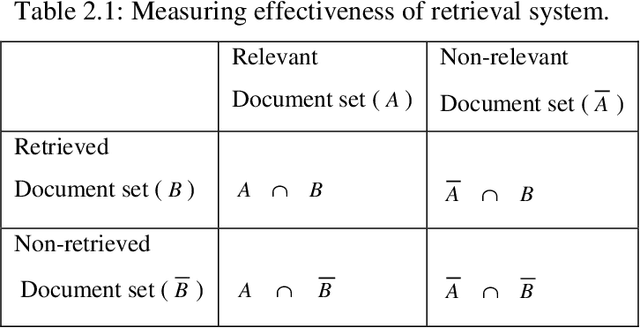
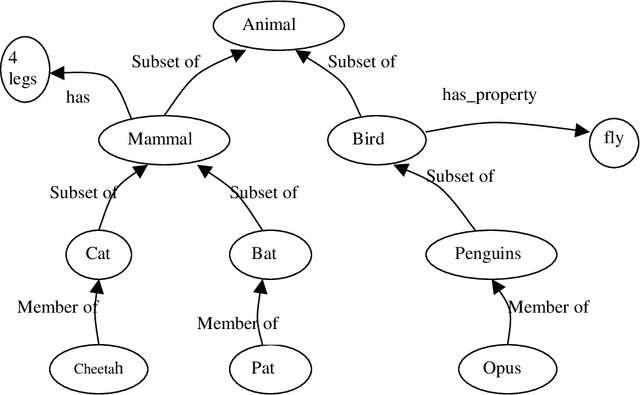

This research work deals with Natural Language Processing (NLP) and extraction of essential information in an explicit form. The most common among the information management strategies is Document Retrieval (DR) and Information Filtering. DR systems may work as combine harvesters, which bring back useful material from the vast fields of raw material. With large amount of potentially useful information in hand, an Information Extraction (IE) system can then transform the raw material by refining and reducing it to a germ of original text. A Document Retrieval system collects the relevant documents carrying the required information, from the repository of texts. An IE system then transforms them into information that is more readily digested and analyzed. It isolates relevant text fragments, extracts relevant information from the fragments, and then arranges together the targeted information in a coherent framework. The thesis presents a new approach for Word Sense Disambiguation using thesaurus. The illustrative examples supports the effectiveness of this approach for speedy and effective disambiguation. A Document Retrieval method, based on Fuzzy Logic has been described and its application is illustrated. A question-answering system describes the operation of information extraction from the retrieved text documents. The process of information extraction for answering a query is considerably simplified by using a Structured Description Language (SDL) which is based on cardinals of queries in the form of who, what, when, where and why. The thesis concludes with the presentation of a novel strategy based on Dempster-Shafer theory of evidential reasoning, for document retrieval and information extraction. This strategy permits relaxation of many limitations, which are inherent in Bayesian probabilistic approach.