 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Classification Model for Igbo Text Using N-Gram And K-Nearest Neighbour Approaches
Paper and Code
Apr 01, 2020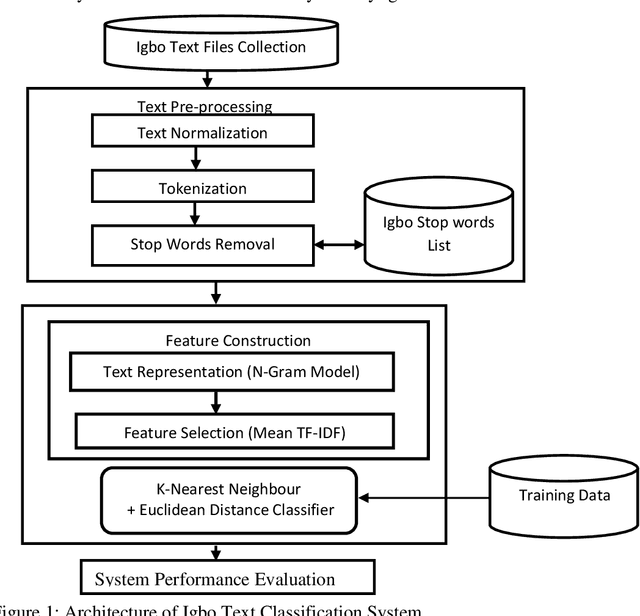


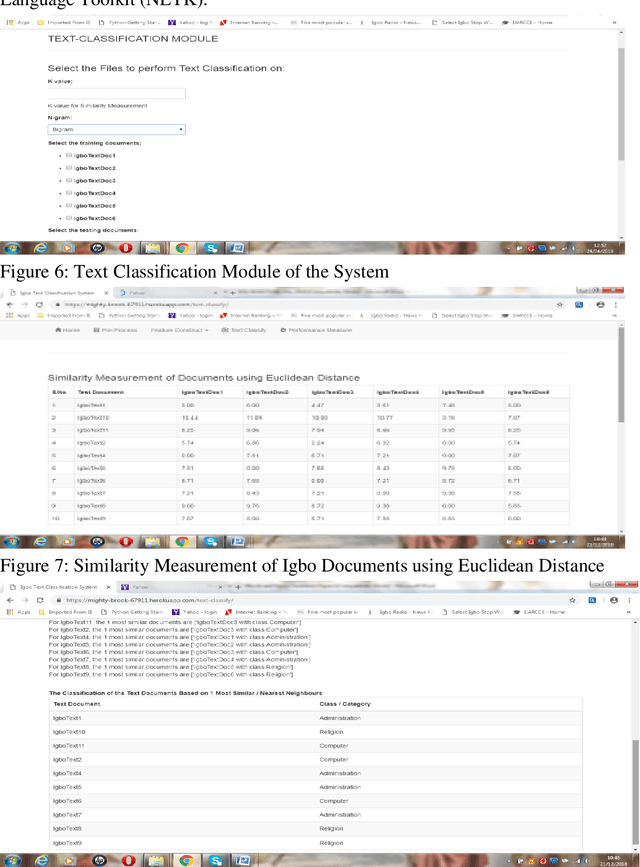
This paper presents an improved classification model for Igbo text using N-gram and K-Nearest Neighbour approaches. The N-gram model was used for text representation and the classification was carried out on the text using the K-Nearest Neighbour model. Object-Oriented design methodology is used for the work and is implemented with the Python programming language with tools from Natural Language Toolkit (NLTK). The performance of the Igbo text classification system is measured by computing the precision, recall and F1-measure of the result obtained on Unigram, Bigram and Trigram represented text. The Igbo text classification on bigram represented text has highest degree of exactness (precision); result obtained with three N-gram models has the same level of completeness (recall) while trigram has the lowest level of precision. This shows that the classification on bigram Igbo represented text outperforms unigram and trigram represented texts. Therefore, bigram text representation model is highly recommended for any intelligent text-based system in Igbo language.