 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Generated Data: Achilles' Heel of BERT
Paper and Code
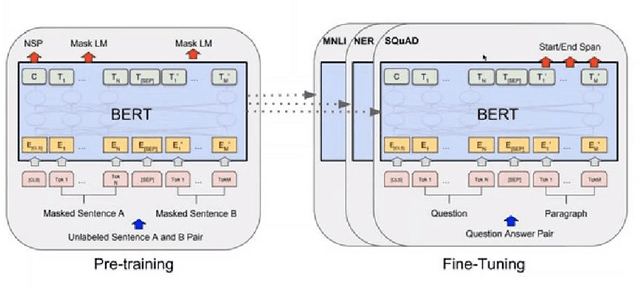

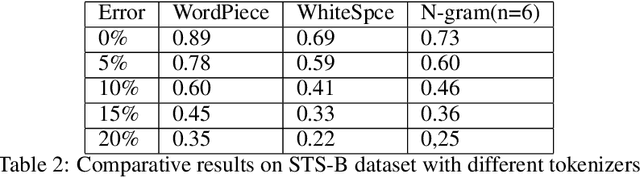
Owing to BERT's phenomenal success on various NLP tasks and benchmark datasets, industry practitioners have started to experiment with incorporating BERT to build applications to solve industry use cases. Industrial NLP applications are known to deal with much more noisy data as compared to benchmark datasets. In this work we systematically show that when the text data is noisy, there is a significant degradation in the performance of BERT. While this work is motivated from our business use case of building NLP applications for user generated text data which is known to be very noisy, our findings are applicable across various use cases in the industry. Specifically, we show that BERT's performance on fundamental tasks like sentiment analysis and textual similarity drops significantly as we introduce noise in data in the form of spelling mistakes and typos. For our experiments we use three well known datasets - IMDB movie reviews, SST-2 and STS-B to measure the performance. Further, we identify the shortcomings in the BERT pipeline that are responsible for this drop in performance.