 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of biterms modeling for short texts
Paper and Code
Mar 26, 2020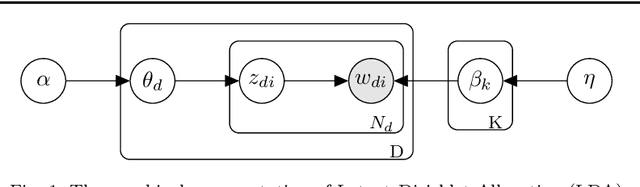

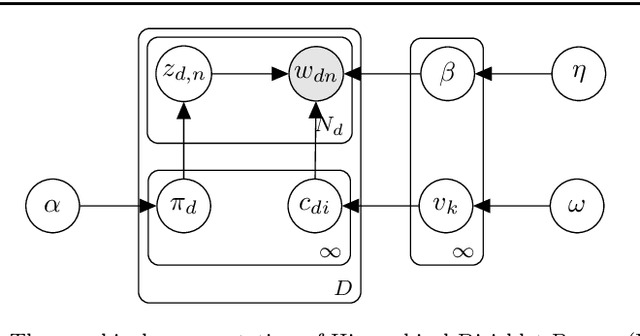

Analyzing texts from social media encounters many challenges due to their unique characteristics of shortness, massiveness, and dynamic. Short texts do not provide enough context information, causing the failure of the traditional statistical models. Furthermore, many applications often face with massive and dynamic short texts, causing various computational challenges to the current batch learning algorithms. This paper presents a novel framework, namely Bag of Biterms Modeling (BBM), for modeling massive, dynamic, and short text collections. BBM comprises of two main ingredients: (1) the concept of Bag of Biterms (BoB) for representing documents, and (2) a simple way to help statistical models to include BoB. Our framework can be easily deployed for a large class of probabilistic models, and we demonstrate its usefulness with two well-known models: Latent Dirichlet Allocation (LDA) and Hierarchical Dirichlet Process (HDP). By exploiting both terms (words) and biterms (pairs of words), the major advantages of BBM are: (1) it enhances the length of the documents and makes the context more coherent by emphasizing the word connotation and co-occurrence via Bag of Biterms, (2) it inherits inference and learning algorithms from the primitive to make it straightforward to design online and streaming algorithms for short texts. Extensive experiments suggest that BBM outperforms several state-of-the-art models. We also point out that the BoB representation performs better than the traditional representations (e.g, Bag of Words, tf-idf) even for normal texts.