 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Yorùbá Diacritic Restoration
Paper and Code

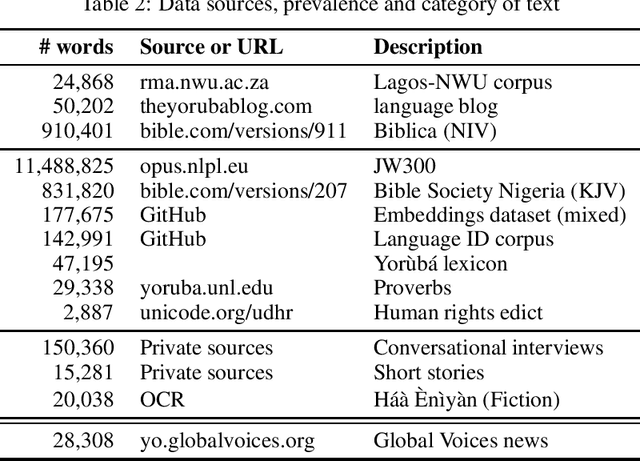
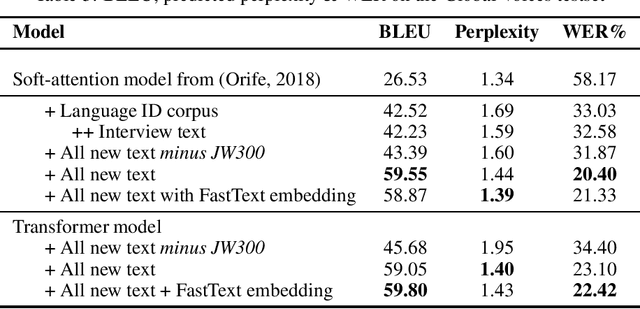
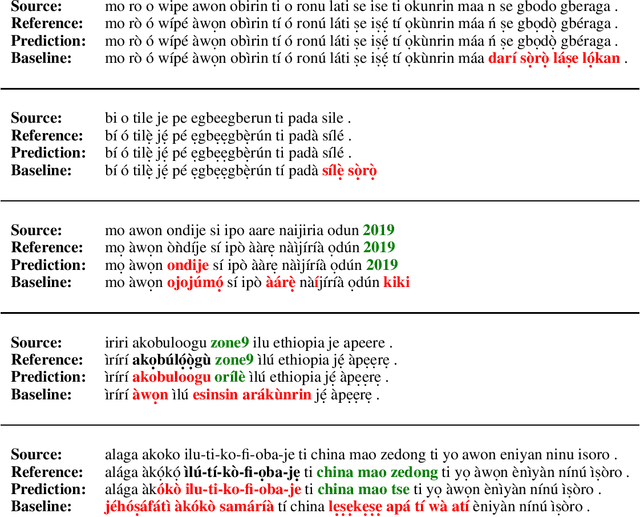
Yor\`ub\'a is a widely spoken West African language with a writing system rich in orthographic and tonal diacritics. They provide morphological information, are crucial for lexical disambiguation, pronunciation and are vital for any computational Speech or Natural Language Processing tasks. However diacritic marks are commonly excluded from electronic texts due to limited device and application support as well as general education on proper usage. We report on recent efforts at dataset cultivation. By aggregating and improving disparate texts from the web and various personal libraries, we were able to significantly grow our clean Yor\`ub\'a dataset from a majority Bibilical text corpora with three sources to millions of tokens from over a dozen sources. We evaluate updated diacritic restoration models on a new, general purpose, public-domain Yor\`ub\'a evaluation dataset of modern journalistic news text, selected to be multi-purpose and reflecting contemporary usage. All pre-trained models, datasets and source-code have been released as an open-source project to advance efforts on Yor\`ub\'a language technology.