 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo CNNs Encode Data Augmentations?
Paper and Code
Feb 29, 2020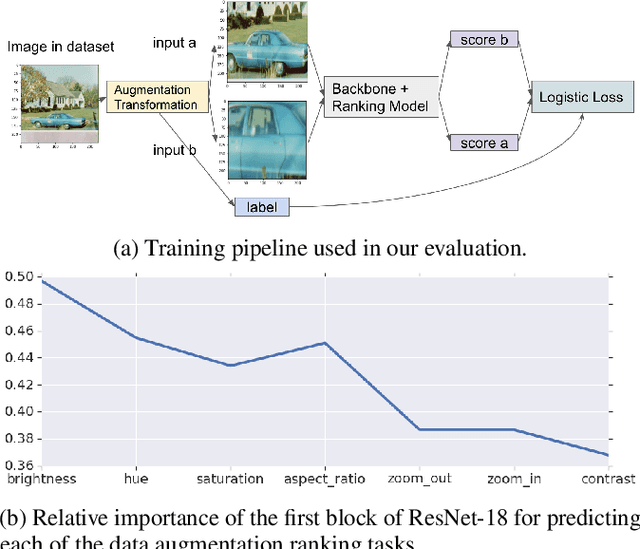
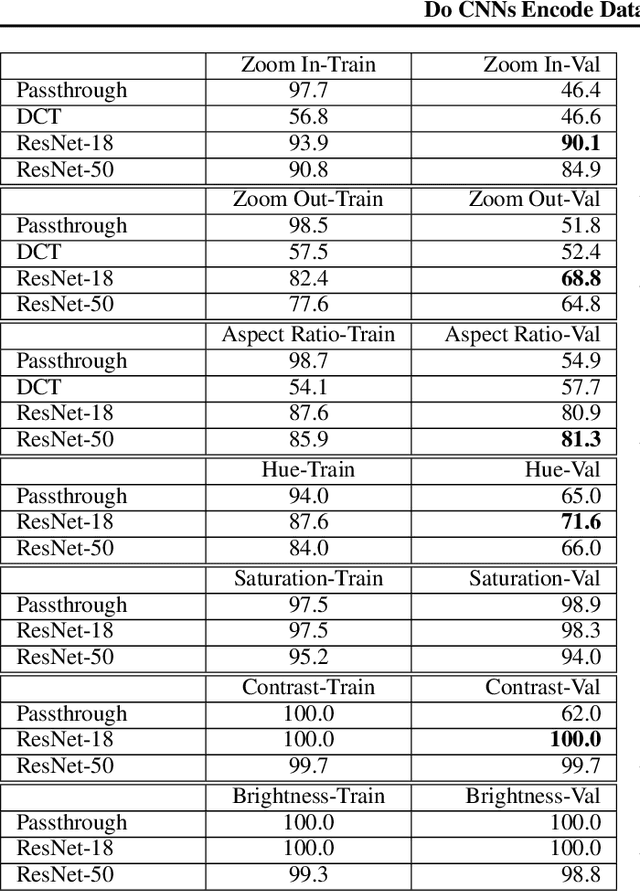

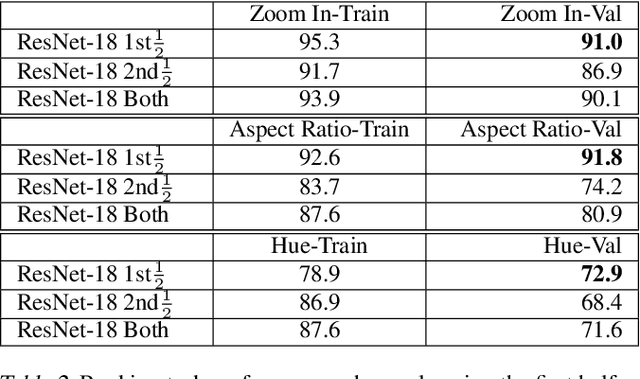
Data augmentations are an important ingredient in the recipe for training robust neural networks, especially in computer vision. A fundamental question is whether neural network features explicitly encode data augmentation transformations. To answer this question, we introduce a systematic approach to investigate which layers of neural networks are the most predictive of augmentation transformations. Our approach uses layer features in pre-trained vision models with minimal additional processing to predict common properties transformed by augmentation (scale, aspect ratio, hue, saturation, contrast, brightness). Surprisingly, neural network features not only predict data augmentation transformations, but they predict many transformations with high accuracy. After validating that neural networks encode features corresponding to augmentation transformations, we show that these features are primarily encoded in the early layers of modern CNNs.