 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Precisely Xtreme-Multi Channel Hybrid Approach For Roman Urdu Sentiment Analysis
Paper and Code
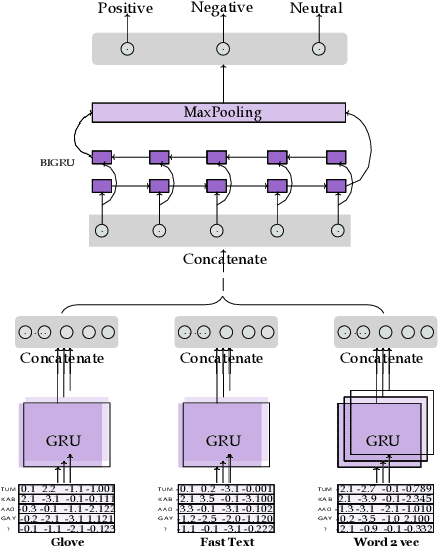
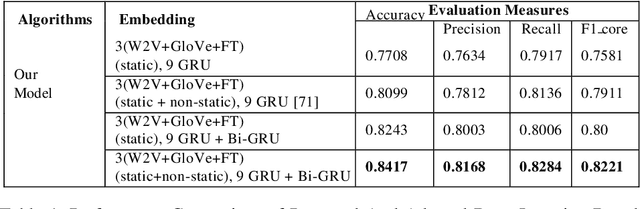
In order to accelerate the performance of various Natural Language Processing tasks for Roman Urdu, this paper for the very first time provides 3 neural word embeddings prepared using most widely used approaches namely Word2vec, FastText, and Glove. The integrity of generated neural word embeddings is evaluated using intrinsic and extrinsic evaluation approaches. Considering the lack of publicly available benchmark datasets, it provides a first-ever Roman Urdu dataset which consists of 3241 sentiments annotated against positive, negative and neutral classes. To provide benchmark baseline performance over the presented dataset, we adapt diverse machine learning (Support Vector Machine Logistic Regression, Naive Bayes), deep learning (convolutional neural network, recurrent neural network), and hybrid approaches. Effectiveness of generated neural word embeddings is evaluated by comparing the performance of machine and deep learning based methodologies using 7, and 5 distinct feature representation approaches respectively. Finally, it proposes a novel precisely extreme multi-channel hybrid methodology which outperforms state-of-the-art adapted machine and deep learning approaches by the figure of 9%, and 4% in terms of F1-score. Roman Urdu Sentiment Analysis, Pretrain word embeddings for Roman Urdu, Word2Vec, Glove, Fast-Text