 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText classification with word embedding regularization and soft similarity measure
Paper and Code
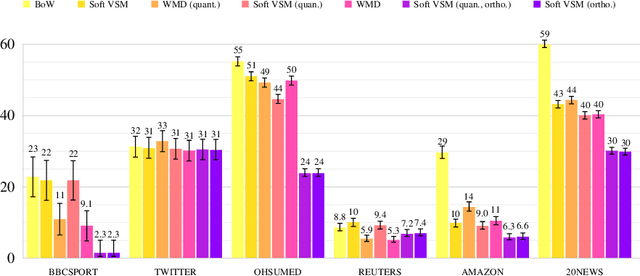
Since the seminal work of Mikolov et al., word embeddings have become the preferred word representations for many natural language processing tasks. Document similarity measures extracted from word embeddings, such as the soft cosine measure (SCM) and the Word Mover's Distance (WMD), were reported to achieve state-of-the-art performance on semantic text similarity and text classification. Despite the strong performance of the WMD on text classification and semantic text similarity, its super-cubic average time complexity is impractical. The SCM has quadratic worst-case time complexity, but its performance on text classification has never been compared with the WMD. Recently, two word embedding regularization techniques were shown to reduce storage and memory costs, and to improve training speed, document processing speed, and task performance on word analogy, word similarity, and semantic text similarity. However, the effect of these techniques on text classification has not yet been studied. In our work, we investigate the individual and joint effect of the two word embedding regularization techniques on the document processing speed and the task performance of the SCM and the WMD on text classification. For evaluation, we use the $k$NN classifier and six standard datasets: BBCSPORT, TWITTER, OHSUMED, REUTERS-21578, AMAZON, and 20NEWS. We show 39% average $k$NN test error reduction with regularized word embeddings compared to non-regularized word embeddings. We describe a practical procedure for deriving such regularized embeddings through Cholesky factorization. We also show that the SCM with regularized word embeddings significantly outperforms the WMD on text classification and is over 10,000 times faster.