 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Information Extraction with Limited Data
Paper and Code
Mar 06, 2020
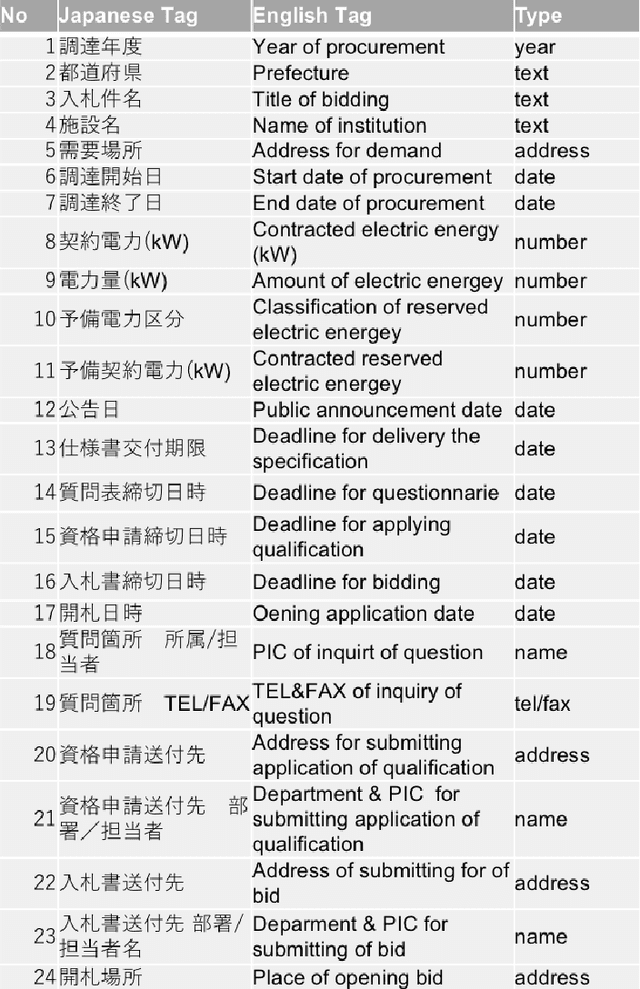

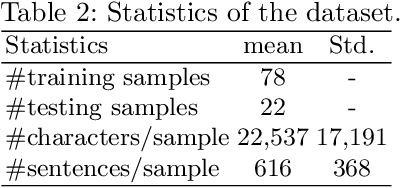
This paper presents a practical approach to fine-grained information extraction. Through plenty of experiences of authors in practically applying information extraction to business process automation, there can be found a couple of fundamental technical challenges: (i) the availability of labeled data is usually limited and (ii) highly detailed classification is required. The main idea of our proposal is to leverage the concept of transfer learning, which is to reuse the pre-trained model of deep neural networks, with a combination of common statistical classifiers to determine the class of each extracted term. To do that, we first exploit BERT to deal with the limitation of training data in real scenarios, then stack BERT with Convolutional Neural Networks to learn hidden representation for classification. To validate our approach, we applied our model to an actual case of document processing, which is a process of competitive bids for government projects in Japan. We used 100 documents for training and testing and confirmed that the model enables to extract fine-grained named entities with a detailed level of information preciseness specialized in the targeted business process, such as a department name of application receivers.