 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Threshold Pruning
Paper and Code
Feb 28, 2020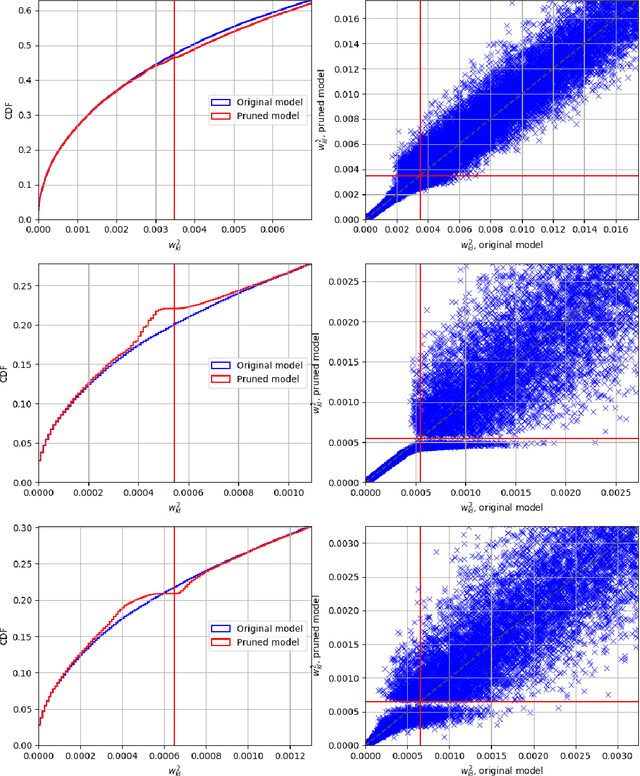
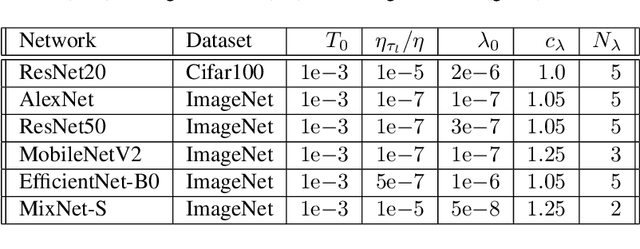
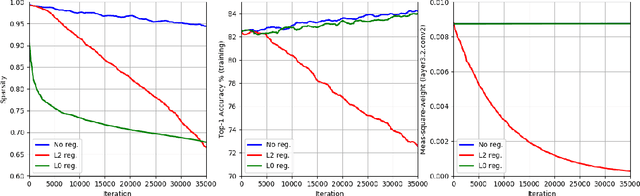
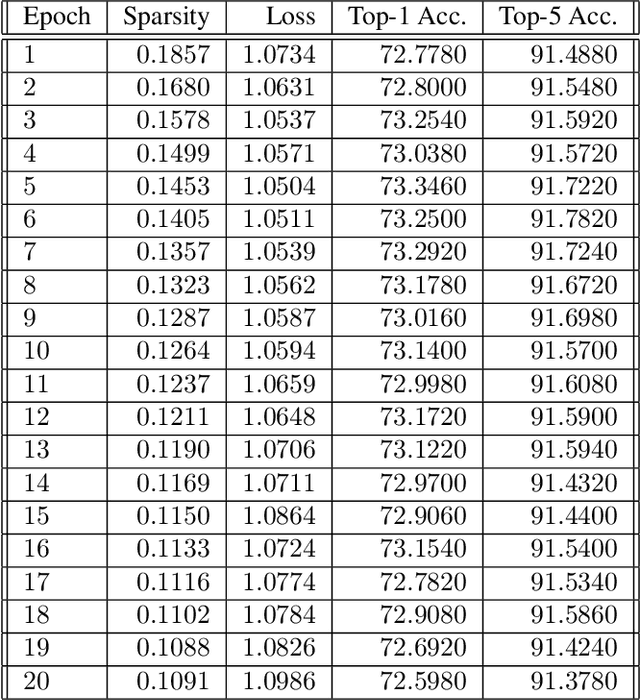
This paper presents a novel differentiable method for unstructured weight pruning of deep neural networks. Our learned-threshold pruning (LTP) method enjoys a number of important advantages. First, it learns per-layer thresholds via gradient descent, unlike conventional methods where they are set as input. Making thresholds trainable also makes LTP computationally efficient, hence scalable to deeper networks. For example, it takes less than $30$ epochs for LTP to prune most networks on ImageNet. This is in contrast to other methods that search for per-layer thresholds via a computationally intensive iterative pruning and fine-tuning process. Additionally, with a novel differentiable $L_0$ regularization, LTP is able to operate effectively on architectures with batch-normalization. This is important since $L_1$ and $L_2$ penalties lose their regularizing effect in networks with batch-normalization. Finally, LTP generates a trail of progressively sparser networks from which the desired pruned network can be picked based on sparsity and performance requirements. These features allow LTP to achieve state-of-the-art compression rates on ImageNet networks such as AlexNet ($26.4\times$ compression with $79.1\%$ Top-5 accuracy) and ResNet50 ($9.1\times$ compression with $92.0\%$ Top-5 accuracy). We also show that LTP effectively prunes newer architectures, such as EfficientNet, MobileNetV2 and MixNet.