 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Computation versus Quality for Neural Sequence Models
Paper and Code
Feb 17, 2020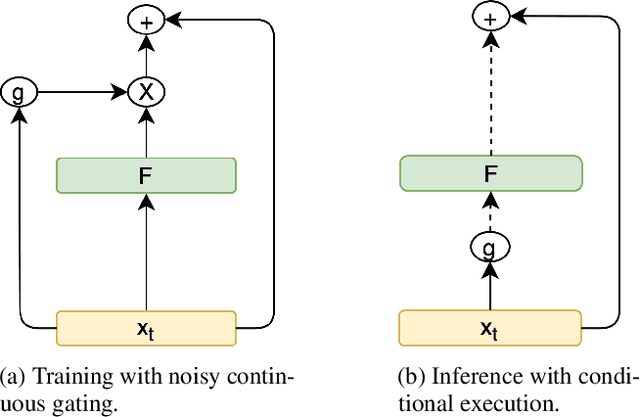
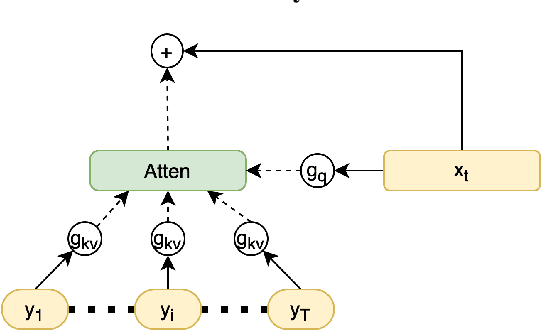
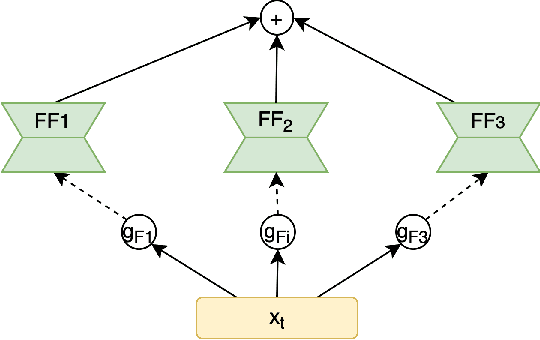
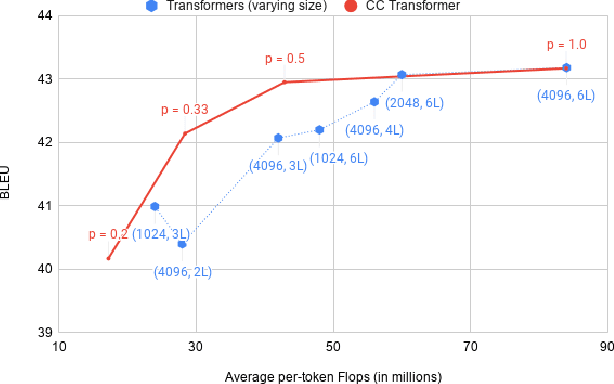
Most neural networks utilize the same amount of compute for every example independent of the inherent complexity of the input. Further, methods that adapt the amount of computation to the example focus on finding a fixed inference-time computational graph per example, ignoring any external computational budgets or varying inference time limitations. In this work, we utilize conditional computation to make neural sequence models (Transformer) more efficient and computation-aware during inference. We first modify the Transformer architecture, making each set of operations conditionally executable depending on the output of a learned control network. We then train this model in a multi-task setting, where each task corresponds to a particular computation budget. This allows us to train a single model that can be controlled to operate on different points of the computation-quality trade-off curve, depending on the available computation budget at inference time. We evaluate our approach on two tasks: (i) WMT English-French Translation and (ii) Unsupervised representation learning (BERT). Our experiments demonstrate that the proposed Conditional Computation Transformer (CCT) is competitive with vanilla Transformers when allowed to utilize its full computational budget, while improving significantly over computationally equivalent baselines when operating on smaller computational budgets.