 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAID: Randomized Adversarial-Input Detection for Neural Networks
Paper and Code
Feb 07, 2020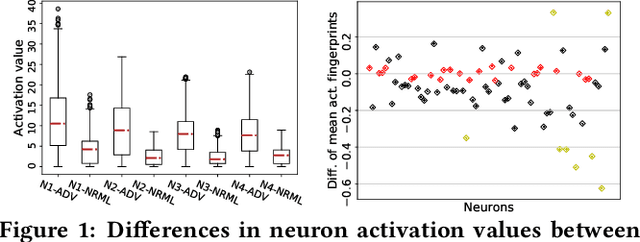
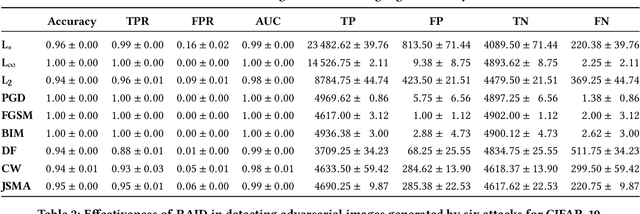
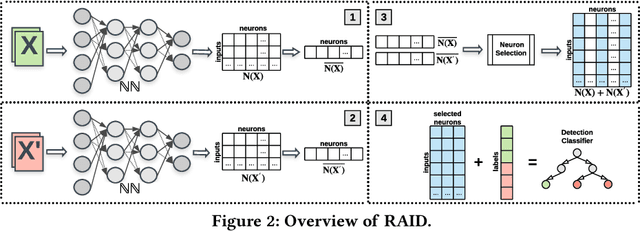
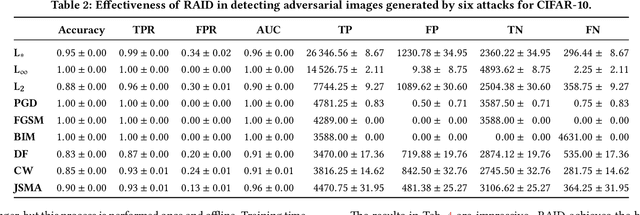
In recent years, neural networks have become the default choice for image classification and many other learning tasks, even though they are vulnerable to so-called adversarial attacks. To increase their robustness against these attacks, there have emerged numerous detection mechanisms that aim to automatically determine if an input is adversarial. However, state-of-the-art detection mechanisms either rely on being tuned for each type of attack, or they do not generalize across different attack types. To alleviate these issues, we propose a novel technique for adversarial-image detection, RAID, that trains a secondary classifier to identify differences in neuron activation values between benign and adversarial inputs. Our technique is both more reliable and more effective than the state of the art when evaluated against six popular attacks. Moreover, a straightforward extension of RAID increases its robustness against detection-aware adversaries without affecting its effectiveness.