 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQWA: Stochastic Quantized Weight Averaging for Improving the Generalization Capability of Low-Precision Deep Neural Networks
Paper and Code
Feb 02, 2020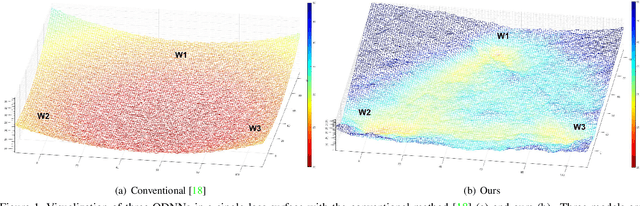
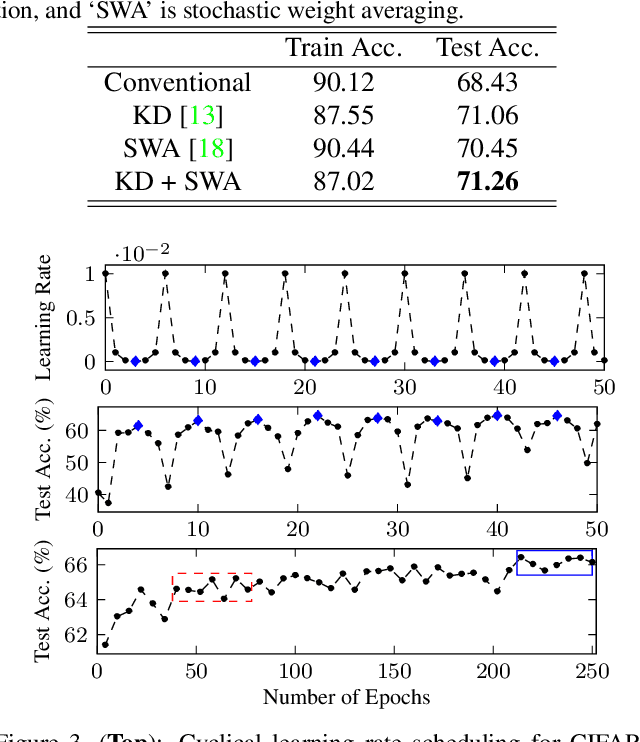
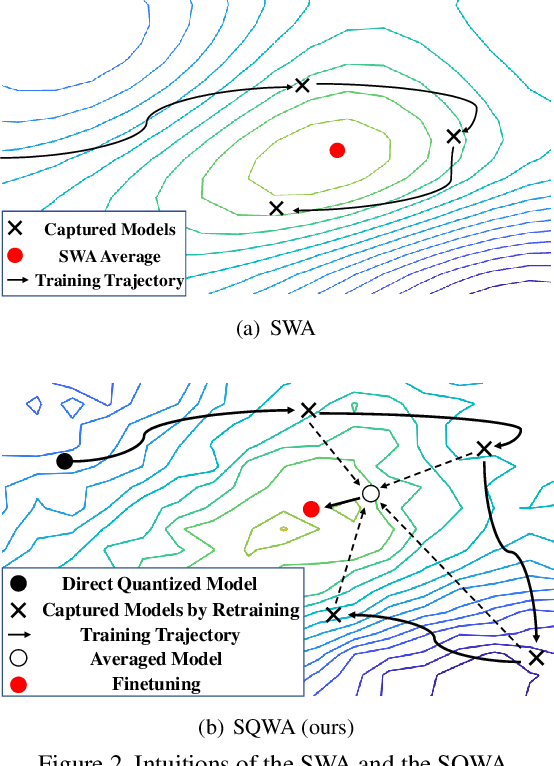
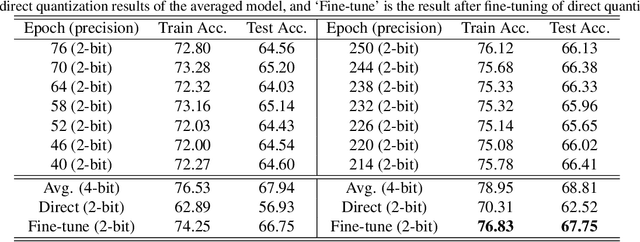
Designing a deep neural network (DNN) with good generalization capability is a complex process especially when the weights are severely quantized. Model averaging is a promising approach for achieving the good generalization capability of DNNs, especially when the loss surface for training contains many sharp minima. We present a new quantized neural network optimization approach, stochastic quantized weight averaging (SQWA), to design low-precision DNNs with good generalization capability using model averaging. The proposed approach includes (1) floating-point model training, (2) direct quantization of weights, (3) capturing multiple low-precision models during retraining with cyclical learning rates, (4) averaging the captured models, and (5) re-quantizing the averaged model and fine-tuning it with low-learning rates. Additionally, we present a loss-visualization technique on the quantized weight domain to clearly elucidate the behavior of the proposed method. Visualization results indicate that a quantized DNN (QDNN) optimized with the proposed approach is located near the center of the flat minimum in the loss surface. With SQWA training, we achieved state-of-the-art results for 2-bit QDNNs on CIFAR-100 and ImageNet datasets. Although we only employed a uniform quantization scheme for the sake of implementation in VLSI or low-precision neural processing units, the performance achieved exceeded those of previous studies employing non-uniform quantization.