 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn interpretable semi-supervised classifier using two different strategies for amended self-labeling
Paper and Code
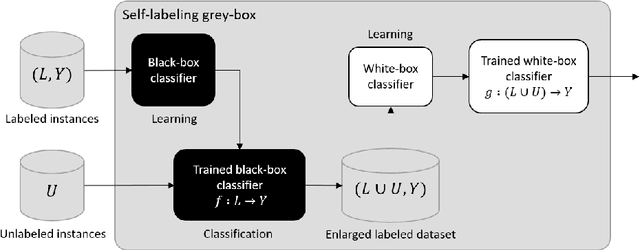
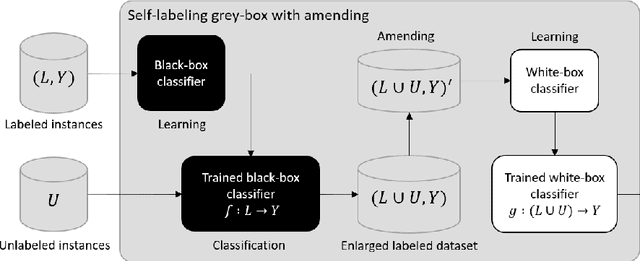
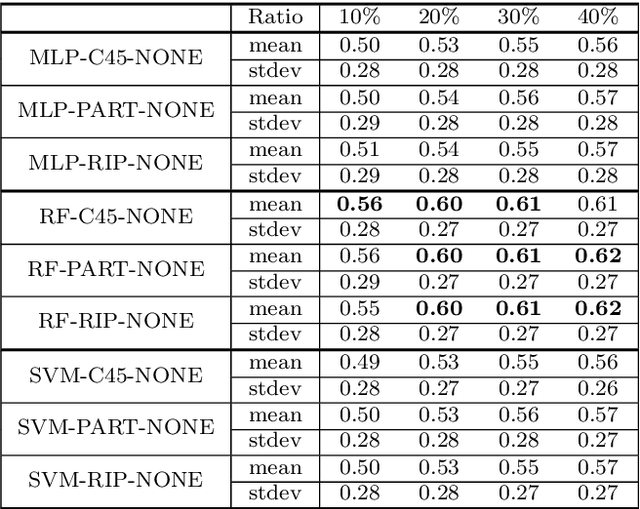
In the context of some machine learning applications, obtaining data instances is a relatively easy process but labeling them could become quite expensive or tedious. Such scenarios lead to datasets with few labeled instances and a larger number of unlabeled ones. Semi-supervised classification techniques combine labeled and unlabeled data during the learning phase in order to increase classifier's generalization capability. Regrettably, most successful semi-supervised classifiers do not allow explaining their outcome, thus behaving like black boxes. However, there is an increasing number of problem domains in which experts demand a clear understanding of the decision process. In this paper, we report on an extended experimental study presenting an interpretable self-labeling grey-box classifier that uses a black box to estimate the missing class labels and a white box to make the final predictions. Two different approaches for amending the self-labeling process are explored: a first one based on the confidence of the black box and the latter one based on measures from Rough Set Theory. The results of the extended experimental study support the interpretability by means of transparency and simplicity of our classifier, while attaining superior prediction rates when compared with state-of-the-art self-labeling classifiers reported in the literature.