 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Language Models using Doped Kronecker Products
Paper and Code
Jan 31, 2020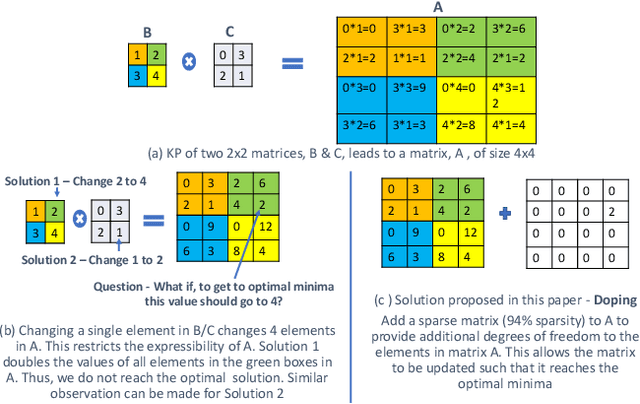
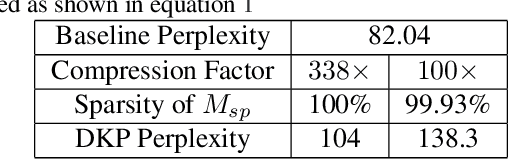
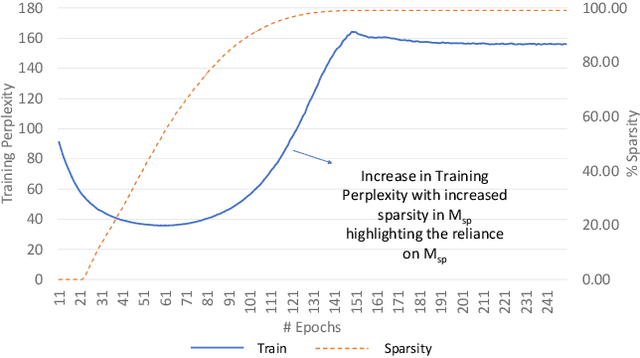
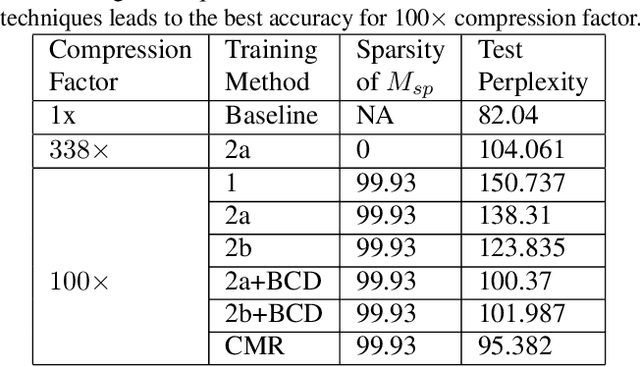
Kronecker Products (KP) have been used to compress IoT RNN Applications by 15-38x compression factors, achieving better results than traditional compression methods. However when KP is applied to large Natural Language Processing tasks, it leads to significant accuracy loss (approx 26%). This paper proposes a way to recover accuracy otherwise lost when applying KP to large NLP tasks, by allowing additional degrees of freedom in the KP matrix. More formally, we propose doping, a process of adding an extremely sparse overlay matrix on top of the pre-defined KP structure. We call this compression method doped kronecker product compression. To train these models, we present a new solution to the phenomenon of co-matrix adaption (CMA), which uses a new regularization scheme called co matrix dropout regularization (CMR). We present experimental results that demonstrate compression of a large language model with LSTM layers of size 25 MB by 25x with 1.4% loss in perplexity score. At 25x compression, an equivalent pruned network leads to 7.9% loss in perplexity score, while HMD and LMF lead to 15% and 27% loss in perplexity score respectively.