 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManyModalQA: Modality Disambiguation and QA over Diverse Inputs
Paper and Code
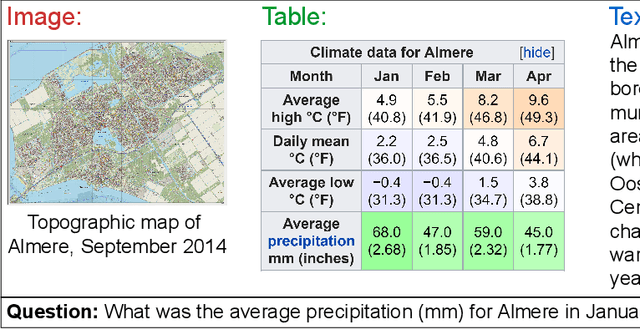

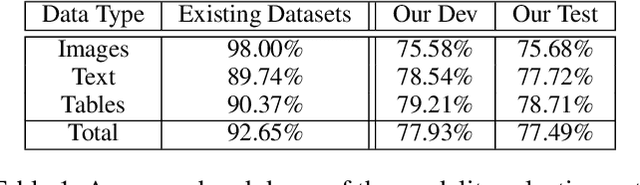
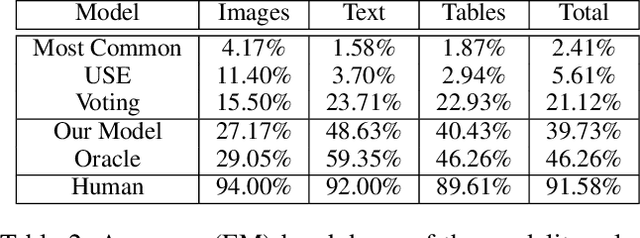
We present a new multimodal question answering challenge, ManyModalQA, in which an agent must answer a question by considering three distinct modalities: text, images, and tables. We collect our data by scraping Wikipedia and then utilize crowdsourcing to collect question-answer pairs. Our questions are ambiguous, in that the modality that contains the answer is not easily determined based solely upon the question. To demonstrate this ambiguity, we construct a modality selector (or disambiguator) network, and this model gets substantially lower accuracy on our challenge set, compared to existing datasets, indicating that our questions are more ambiguous. By analyzing this model, we investigate which words in the question are indicative of the modality. Next, we construct a simple baseline ManyModalQA model, which, based on the prediction from the modality selector, fires a corresponding pre-trained state-of-the-art unimodal QA model. We focus on providing the community with a new manymodal evaluation set and only provide a fine-tuning set, with the expectation that existing datasets and approaches will be transferred for most of the training, to encourage low-resource generalization without large, monolithic training sets for each new task. There is a significant gap between our baseline models and human performance; therefore, we hope that this challenge encourages research in end-to-end modality disambiguation and multimodal QA models, as well as transfer learning. Code and data available at: https://github.com/hannandarryl/ManyModalQA